Langchain pt. 3 - Come invocare API Rest in linguaggio naturale
Intro
L’anno scorso, Gartner ha inserito la Generative AI nella fase di picco di aspettative all’interno del suo modello di Hype Cycle per il mondo della AI.
Recentemente alcuni nomi importanti tra le grandi aziende del settore hanno paragonato l’entusiasmo della GenAI alla bolla dotcom. Inoltre sono circolate delle indiscrezioni intorno ai principali Cloud Providers, secondo le quali essi stiano addirittura dando indicazioni ai loro Sales Team di rallentare l’entusiasmo dimostrato verso i clienti nei confronti delle iniziative di GenAI, o comunque di utilizzare un approccio cauto e consapevole dei costi e dei reali benefici. E’ già iniziata la discesa verso la “fossa della disillusione”?
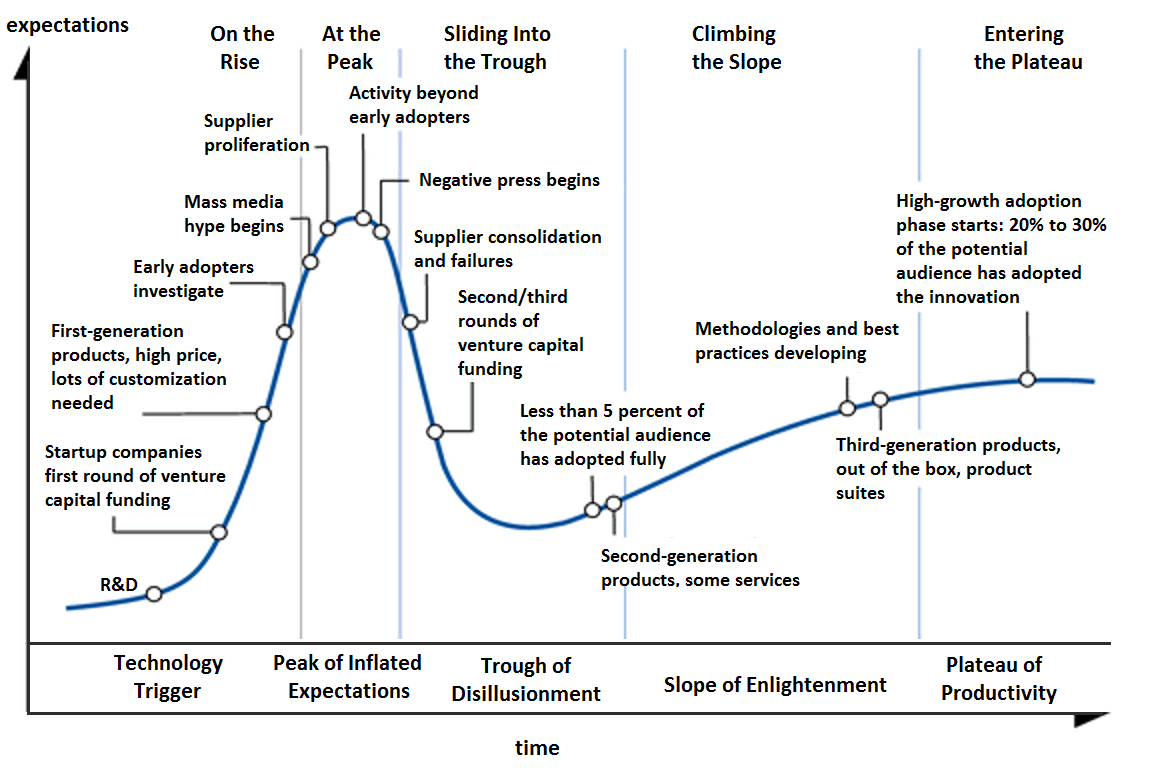
D’altro canto, è anche possibile che questa volta il classico modello Hype Cycle non sia applicabile . Rispetto ad altri trend trasformativi e tecnologici, si sta andando molto velocemente a regime verso una fase di consapevolezza e maturazione. Si iniziano infatti a vedere alcuni trend del mercato, che vanno oltre la semplice corsa al modello più potente in termini di “forza bruta”.
Alcuni esempi:
- Molte aziende stanno lavorando su modelli relativamente piccoli ed eseguibili anche in locale, esempi:
- Meta e Qualcomm hanno appena annunciato un accordo di collaborazione per l’ottimizzazione dei modelli Llama3 al fine di essere eseguiti direttamente sui dispositivi equipaggiati con le future piattaforme top di gamma Snapdragon
- H2O ha lanciato un modello linguistico superleggero denominato Danube, derivato da Llama2 e pensato per essere eseguito su device mobili
- Apple sembra stia lavorando ad un modello linguistico “on-device” e disponibile offline sui dispositivi di Cupertino
- Più o meno tutti i grandi sviluppatori di LLM stanno introducendo delle soluzioni multi-modali
- Stanno nascendo diversi framework e prodotti che permettono di costruire soluzioni complesse e modulari e che utilizzano i modelli LLM come building block per costruire applicazioni “AI-powered” complesse e vendor-agnostic
- In altre parole, per fare un parallelo con quello che è successo ormai molti anni fa con la nascita dell’ingegneria del software, tali prodotti stanno spianando la strada alla “Ingegneria dell’AI”
Relativamente a quest’ultimo punto, LangChain va proprio in questa strada. E’ uno dei framework per l’AI Open Source al momento più completi e potenti. Fornisce un grande controllo e adattabilità per vari casi d’uso e offre una maggiore granularità rispetto ad altri framework come, ad esempio, LlamaIndex. Una delle features che ho testato in questi giorni è l’integrazione del framework con API Rest esterne, specificate secondo uno standard preciso (es: Swagger, OpenApi) o anche descritte in linguaggio naturale.
In questo articolo, mostrerò come sia possibile integrare direttamente “a runtime” una API di terze parti all’interno di un banalissimo chatbot, ed interrogare l’API in linguaggio naturale senza alcuna preventiva conoscenza delle specifiche di tale API.
Preambolo tecnico
Il codice mostrato nel seguito e che condivido su GitHub si basa sull’utilizzo di OpenAI e di Bedrock. Quest’ultimo, per chi non lo conoscesse, è il servizio di AWS che dà accesso a diversi modelli tra cui Llama2, Claude, Mistral e il modello proprietario di AWS denominato Titan. Il codice è estremamente semplice e segue i seguenti step logici:
- Inizializzazione delle variabili di ambiente
- Creazione del modello LLM
- Retrieve dinamico delle specifiche di una determinata API
- Inizializzazione e invocazione del componente APIChain. Questo componente, nello specifico, applica alcune semplici tecniche di Prompt Engineering per eseguire le seguenti 3 azioni:
- Prendere in input la domanda dell’utente in linguaggio naturale e costruire, tramite il LLM, l’URL da invocare
- Invocare l’URL così costruito tramite una chiamata HTTP
- Inglobare la risposta ottenuta dalla chiamata HTTP all’interno di una nuova invocazione del LLM ed estrapolare l’informazione richiesta dall’utente
Il processo è riassunto nel seguente diagramma di flusso:
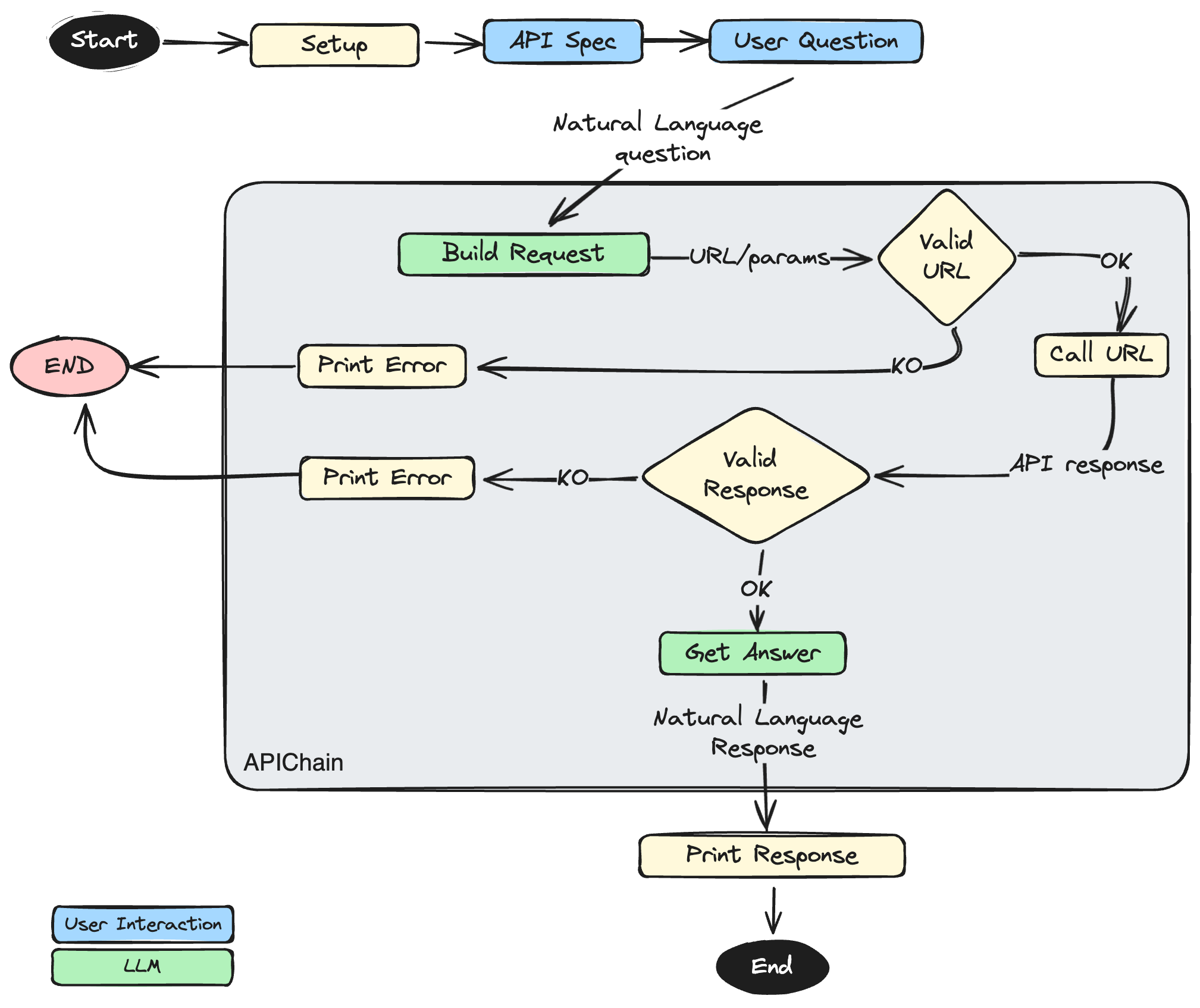
Nel codice che seguirà, ho cablato per semplicità anche le interazioni utente nel codice sotto forma di stringhe statiche, ma nulla vieta di ottenere dinamicamente questi input dall’utente, ad esempio tramite una interfaccia a Chatbot, oppure configurare le API da una apposita sezione applicativa e fare poi plug&play direttamente nel chatbot per aggiungere funzionalità a runtime.
In altre parole, con pochissimo sforzo, è possibile realizzare un chatbot completamente agnostico rispetto alle specifiche API e adeguarsi dinamicamente alle esigenze, inserendo liberamente i riferimenti a nuove API o recependo al volo le eventuali modifiche alla interfaccia.
Il caso d’uso più immediato potrebbe essere, ad esempio, quello di uno strumento di customer care che si integra con le API aziendali per restituire direttamente al cliente informazioni relative ai suoi ordini, prodotti, segnalazioni etc. La disponibilità di queste informazioni potrebbe essere infatti sviluppata in maniera incrementale, potenziando le funzionalità esposte dal chatbot senza tuttavia toccare una riga di codice ed utilizzando un approccio plug&play delle API all’interno del processo dialogico esistente.
Allargando il discorso e andando verso un contesto più Enterprise, possiamo immaginare lo scenario di una moderna Data Platform che metta a disposizione i principali KPI aziendali sotto forma di Data-APIs a beneficio di chiunque in azienda voglia consultarli rapidamente tramite il chatbot aziendale.
In altre parole, le possibilità sono tantissime.
Le API
Le API che ho utilizzato per fare le prove sono le seguenti:
- klarna.com
- per chi non la conoscesse, KLARNA è una fintech svedese che offre una piattaforma di pagamento a rate per chi fa shopping online. E’ integrata in tantissime piattaforme di shopping online. L’API in questione è accessibile gratuitamente, mette a disposizione un metodo per cercare prodotti sulla base di attributi descrittivi, prezzo, brand etc ed è operativa solo in alcuni mercati (US, GB, DE, SE, DK).
- open-meteo
- E’ una API gratuita che mette a disposizione dati meteoreologici. Il caso più comune è quello in cui interroghiamo l’API per ottenere le condizioni meteo in una determinata città, in termini di temperatura, precipitazioni, visibilità, etc.
APIChain
Il componente che andremo ad utilizzare all’interno della suite di LangChain si chiama APIChain ed è banalmente un wrapper che contiene:
- Una istanza di un LLMChain, che serve per costruire l’URL e i parametri HTTP a partire dalla domanda in linguaggio naturale
- Un wrapper del componente request, che viene utilizzato per inviare la chiamata HTTP
- Una istanza di un LLMChain che serve per costruire la response in linguaggio naturale a partire dal payload della Response HTTP
- Alcuni prompt che servono per creare il contesto corretto e implementare efficacemente le chiamate al LLM
Per quanto riguarda i Prompt che mette a disposizione il componente APIChain, durante i test mi sono reso conto che essi non funzionavano correttamente con tutti i LLM (ad es: funzionavano con OpenAI, ma non con Llama2, Claude, etc). Pertanto, ho costruito una versione leggermente migliore del prompt e ho proposto la modifica sul repo ufficiale (vedremo se l’accetteranno 😃 ).
Il Test
Nella prima parte del codice facciamo l’inizializzazione dei componenti di base e creiamo i modelli.
Alcune note:
- le variabili di ambiente relative alla integrazione con OPEN_AI e AWS devono essere configurate nel file .env
- all’interno del file “libs.py” ho creato un wrapper per l’istanziazione del modello LLM. Troverete tutto nel repository GitHub
- I modelli di Bedrock che ho utilizzato si trovano al momento solo in alcune Region. Dunque occorre fare attenzione alle impostazioni della region e dei costi associati all’utilizzo
from langchain.chains import APIChain
from dotenv import load_dotenv
import httpx
import logging as logger
import sys
# see "libs.py" file
from libs import *
# see "prompt_improved.py" file
from prompt_improved import *
# Set WARNING Logger levels help print only meaningful text
logger.basicConfig(stream=sys.stdout, level=logger.WARNING)
logger.getLogger('botocore').setLevel(logger.WARNING)
logger.getLogger('httpx').setLevel(logger.WARNING)
# loading ENV variables
load_dotenv()
# Initialize Models
gpt35 = create_llm(model={"provider":"OpenAI", "value": "gpt-3.5-turbo"}, model_kwargs={"temperature": 0.1})
gpt4 = create_llm(model={"provider":"OpenAI", "value": "gpt-4"}, model_kwargs={"temperature": 0.1})
claude3 = create_llm(model={"provider":"Anthropic", "value": "anthropic.claude-3-sonnet-20240229-v1:0"}, model_kwargs={"temperature": 0.1})
llama2 = create_llm(model={"provider":"Meta", "value": "meta.llama2-70b-chat-v1"}, model_kwargs=None)Ok, adesso vediamo come integrare dinamicamente il file descrittore della interfaccia e passarlo al componente APIChain. La variabile “limit_to_domains” è utilizzata per introdurre un meccanismo di sicurezza che limita i domini verso cui indirizzare le richieste. In teoria potrebbe essere impostato a “None” per non impostare alcun vincolo, ma è sempre preferibile evitarlo. Le 2 variabili api_url_prompt e api_response_prompt consentono di customizzare i prompt da passare all’LLM. Come ho anticipato in precedenza, ho impostato 2 prompt che si sono dimostrati più robusti di quelli di default.
# Dynamically retrieve swagger
output = httpx.get("https://www.klarna.com/us/shopping/public/openai/v0/api-docs/")
swagger = output.text
# build the APIChain
chain = APIChain.from_llm_and_api_docs(
llm=gpt4,
api_docs=swagger,
verbose=False,
limit_to_domains=["klarna.com", "https://www.klarna.com/", "https://www.klarna.com"],
api_url_prompt=FINE_TUNED_API_URL_PROMPT,
api_response_prompt=FINE_TUNED_API_RESPONSE_PROMPT
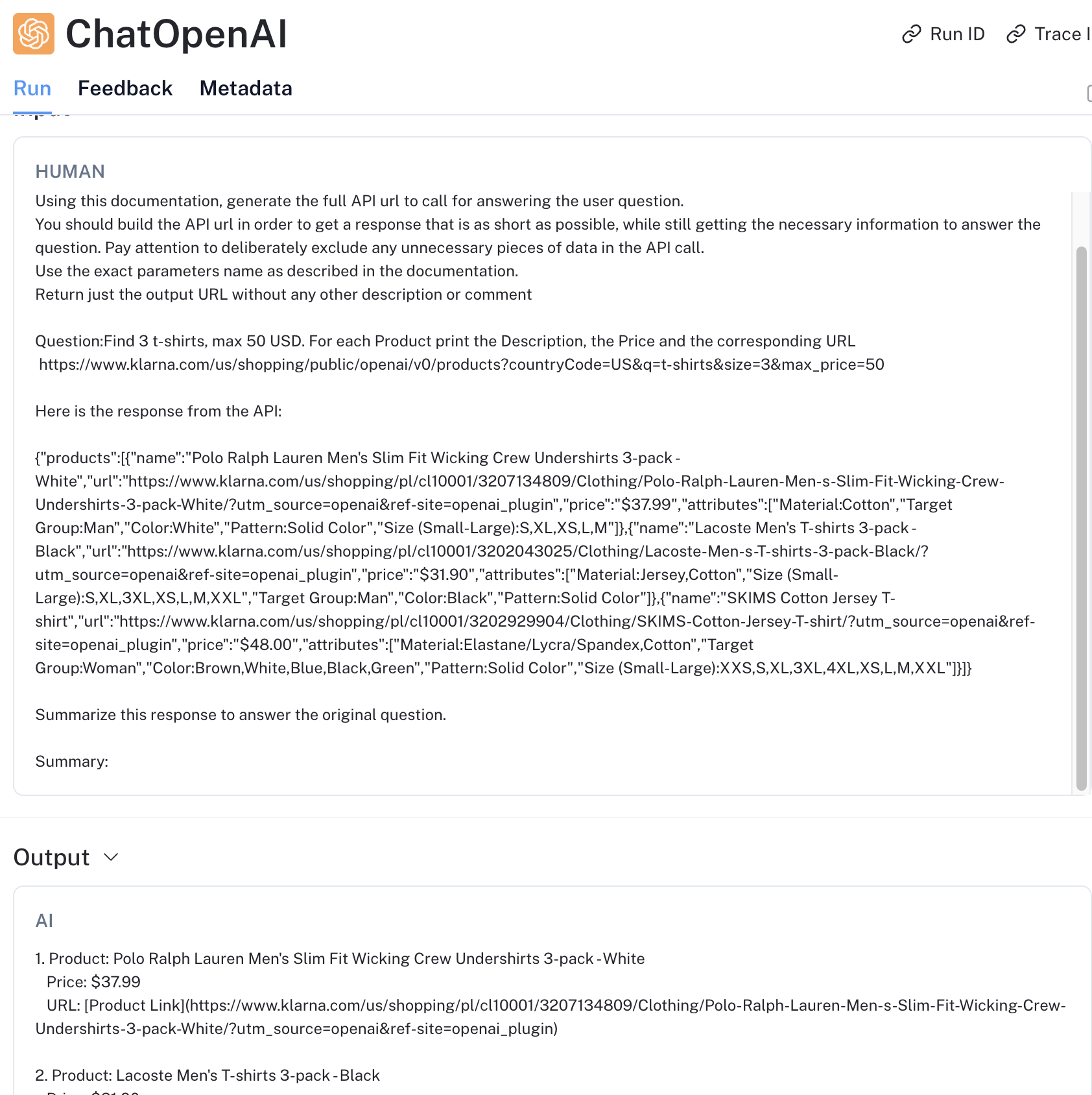
)A questo punto è tutto impostato. Possiamo fare una domanda e passarla al framework per poi restituire l’output all’utente finale. Ho chiesto di ricercare 3 magliette con un tetto massimo di 50 dollari e di ritornare prezzo, descrizione e link.
# Ask a question to the Chain
response = chain.invoke(
"Find 3 t-shirts, max 50 USD. For each Product print the Description, the Price and the corresponding URL"
)
# Print the Chain Output
print(response['output'])Questo è l’output che ho ottenuto al primo tentativo:
1. *Product: Polo Ralph Lauren Men's Slim Fit Wicking Crew Undershirts 3-pack - White*
*Price: $37.99*
*URL: https://www.klarna.com/us/shopping/pl/cl10001/3207134809/Clothing/Polo-Ralph-Lauren-Men-s-Slim-Fit-Wicking-Crew-Undershirts-3-pack-White/?utm_source=openai&ref-site=openai_plugin*
2. *Product: Lacoste Men's T-shirts 3-pack - Black*
*Price: $31.90*
*URL: https://www.klarna.com/us/shopping/pl/cl10001/3202043025/Clothing/Lacoste-Men-s-T-shirts-3-pack-Black/?utm_source=openai&ref-site=openai_plugin*
3. *Product: SKIMS Cotton Jersey T-shirt*
*Price: $48.00*
*URL: https://www.klarna.com/us/shopping/pl/cl10001/3202929904/Clothing/SKIMS-Cotton-Jersey-T-shirt/?utm_source=openai&ref-site=openai_plugin*Non male!
Ho fatto parecchie altre prove con gli altri modelli e ho ottenuto performance simili anche se, come mi aspettavo, GPT4 e Claude3 sono mediamente più precisi.
Per quanto riguarda la seconda API, il codice è praticamente identico, a parte il riferimento all’URL descrittore (swagger), la variabile limit_to_domains che deve essere coerente con l’API e la domanda dell’utente. Riporto dunque solo la seconda e la terza parte dello script python.
Punto di attenzione: non esiste uno swagger ufficiale per questa API, quindi ho usato il file YAML che si trova su GitHub. A volte le chiamate verso GitHub vanno in errore. In tal caso suggerisco di riprovare un paio di volte.
# Dynamically retrieve swagger
output = httpx.get("https://raw.githubusercontent.com/open-meteo/open-meteo/main/openapi.yml")
meteo_swagger = output.text
# build the APIChain
chain = APIChain.from_llm_and_api_docs(
llm=claude3,
api_docs=meteo_swagger,
verbose=True,
limit_to_domains=None,
api_url_prompt=FINE_TUNED_API_URL_PROMPT,
api_response_prompt=FINE_TUNED_API_RESPONSE_PROMPT
)
# Ask a question to the Chain
response = chain.invoke(
"What is the weather like right now in Munich, Germany in degrees Fahrenheit?"
)
# Print the Chain Output
print(response['output'])Il risultato con Claude, e con GPT 3,5 e GPT4 è in linea con le aspettative. Le 2 chiamate di Langchain hanno costruito correttamente l’URL ed interpretato il risultato, trasformandolo in linguaggio naturale.
The current weather in Munich, Germany is 45.7°F with a wind speed of 17.7 km/h coming from 264° direction.Il test con Llama2 non è andato a buon fine. In particolare, ha evidentemente avuto allucinazioni nella prima chiamata, in cui LangChain crea l’URL, inventando alcuni parametri non specificati nello swagger.
Dietro le quinte
Un altro tool molto interessante della suite di LangChain si chiama LangSmith, che consente di fare monitoraggio e profiling su tutte le invocazioni del modello. Oltre a questo, consente di fare tante altre cose, come ad esempio:
- il debugging avanzato
- la continua valutazione dei task tramite la definizione di dataset predefiniti e di criteri di valutazione
- l’annotazione dei modelli per aggiungere metadati o feedback utente
- molte altre features relative al monitoraggio e al miglioramento delle applicazioni basate su LangChain
Utilizzando LangSmith, è possibile vedere graficamente il macroprocesso le chiamate ai modelli sottostanti.
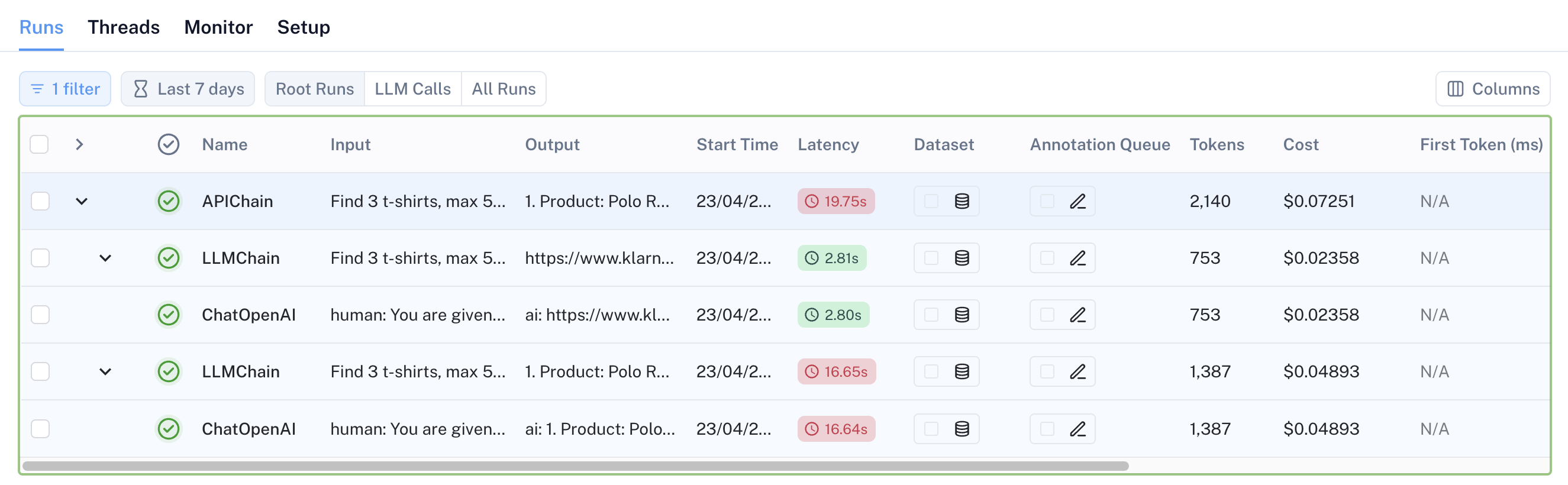
In particolare, in Figura 3, si vede chiaramente la struttura ad albero delle chiamate, identificata dalla sigla “APIChain”, che è composta da 2 chain figlie di tipo LLM, a cui corrispondono altrettante chiamate verso OpenAI. Altra cosa estremamente utile è il numero di token utilizzati e il costo stimato delle singole chiamate.
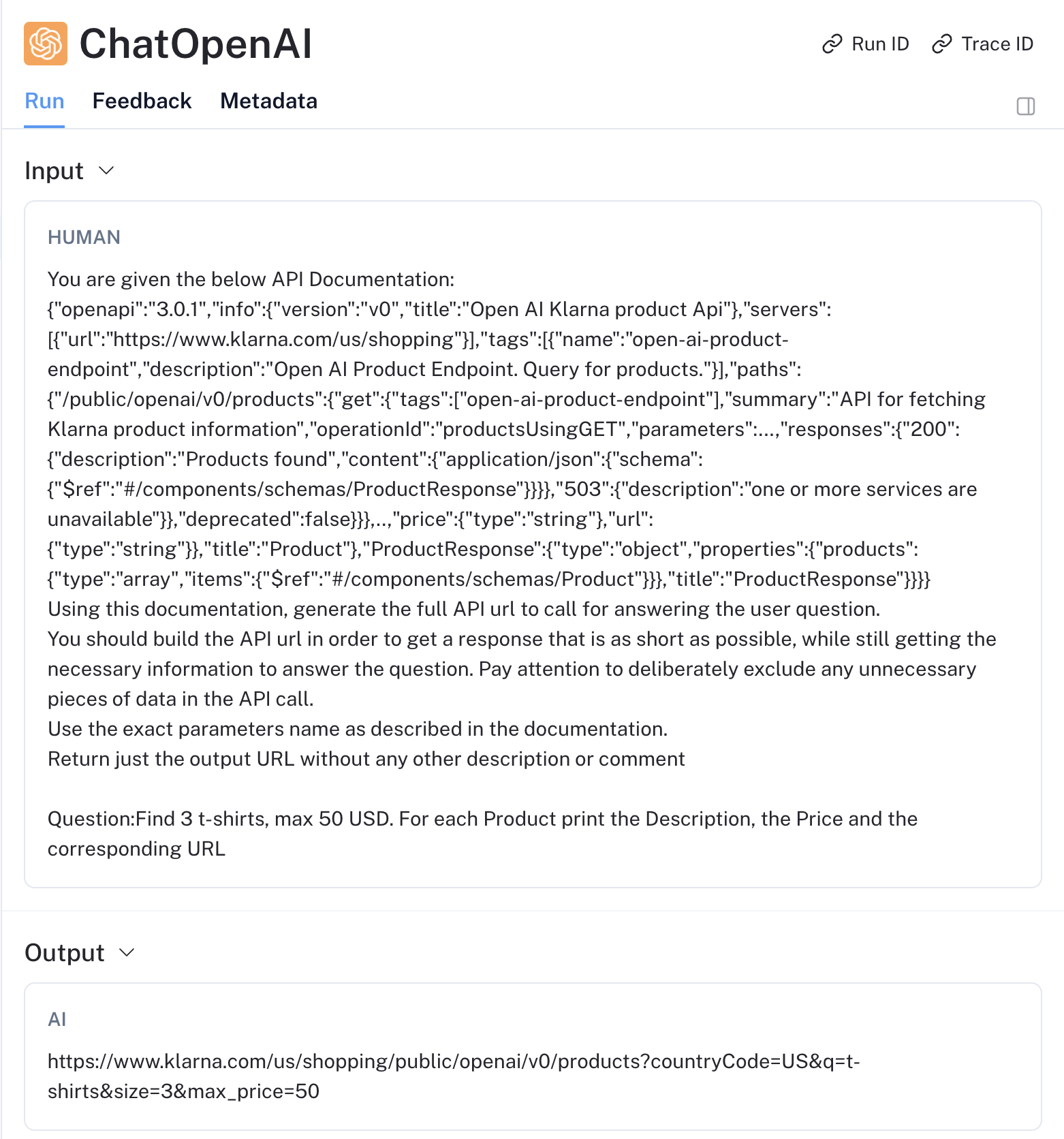
Andando nel dettaglio sulle singole chiamate al LLM, possiamo vedere il prompt realmente passato in input al modello e la response sulla singola invocazione.
Conclusioni
Dando un occhio al codice sorgente di LangChain e alle chiamate che vengono fatte verso i modelli, tramite LangSmith, si vede chiaramente che l’integrazioni di API Rest in una applicazione basata su LLM è veramente banale e basata su tecniche molto semplici di Prompt Engineering, che però consentono una integrazione estremamente potente tra le nuove applicazioni AI e i sistemi tradizionali.
A mio avviso, è uno degli esempi più chiari e cristallini di come oggi si possa (e forse si debba) reinterpretare l’interazione uomo/macchina in termini di integrazione tra sistemi formali ben specificati con comportamento predicibile (es: qualunque sistema software tradizionale in azienda) e il linguaggio naturale.
LangChain ed altri framework consentono di fare qualcosa di simile anche a livello più basso, ad esempio interrogando un DB in linguaggio naturale e utilizzando un LLM per generare le query sottostanti. Al di là delle questioni squisitamente tecniche e di performance, questo approccio è bello in teoria ma, sulla base della mia esperienza, ci sono diversi elementi che mi fanno pensare che esso non sia realmente applicabile se non in alcuni casi specifici poiché nella stragrande maggioranza dei casi ci sono stratificazioni applicative che durano anni e difficoltà a mantenere un data catalog auto-descrittivo di buon livello. Al contrario, le API enterprise introducono un layer che quasi sempre parla una lingua più vicina al Business ed in generale hanno dei metadati auto-descrittivi.