Langchain pt. 2 - Analisi dati tramite Agenti
Intro
Nel precedente articolo ho fatto una brevissima panoramica di LangChain, descrivendone i concetti principali e raccontando un esempio di caso d’uso con dati non strutturati in formato pdf.
Seguendo lo stesso approccio, in questo articolo faremo una breve introduzione sugli Agenti e procederemo provando a rispondere ad una domanda ambiziosa:
è possibile, tramite l’AI, fare analisi sui dati presenti in un DB senza alcuna conoscenza di SQL né tantomeno del modello dati, a partire semplicemente da un prompt testuale in lingua naturale?
Agenti
I LLM sono estremamente potenti, ma possono rivelarsi inefficaci nel rispondere a domande che richiedono una conoscenza di dettaglio non strettamente integrata nel training del modello. In rete esistono decine di esempi che riescono a cogliere in fallo ChatGPT tramite allucinazioni o mancata risposta (es: previsioni meteo, ultime notizie, gossip o anche operazioni matematiche particolari).
I framework come LangChain possono superare queste limitazioni tramite la definizione di componenti specifici e “data-aware”, ma solitamente le azioni eseguite dal framework sono predeterminate. In altre parole, il framework utilizza un Language Model per eseguire delle azioni, ma esse sono “hardcoded” e in moltissimi casi questo può rendere del tutto inefficaci i modelli di AI, perché non si riesce ad aggiungere quel livello di dinamismo tale da pilotare le specifiche azioni sulla base dell’input utente.
E’ qui che entrano in gioco gli “Agent”.
Gli Agent sono dei componenti che hanno a disposizione una serie di Tool per svolgere delle azioni specifiche, come ad esempio fare una ricerca su Wikipedia o su Google, o eseguire codice Python o addirittura accedere al file system locale.
Gli Agent utilizzano un LLM per interpretare l’input dell’utente e decidere di volta come procedere, cioè:
- Quale tool utilizzare tra gli N a disposizione
- Cosa passare come input al tool
- Decidere se si è riusciti ad ottenere una risposta al quesito iniziale oppure ripetere gli step 1 e 2
Questo approccio prende ispirazione da un framework denominato ReAct che è stato definito a fine 2022 da un team congiunto di ricercatori di Google e della Princeton University, che trovate descritto qui. In LangChain, ne esistono diverse implementazioni, ma la più comune prende il nome di “Zero-shot ReAct” e può essere schematizzata secondo il workflow in Figura 1.
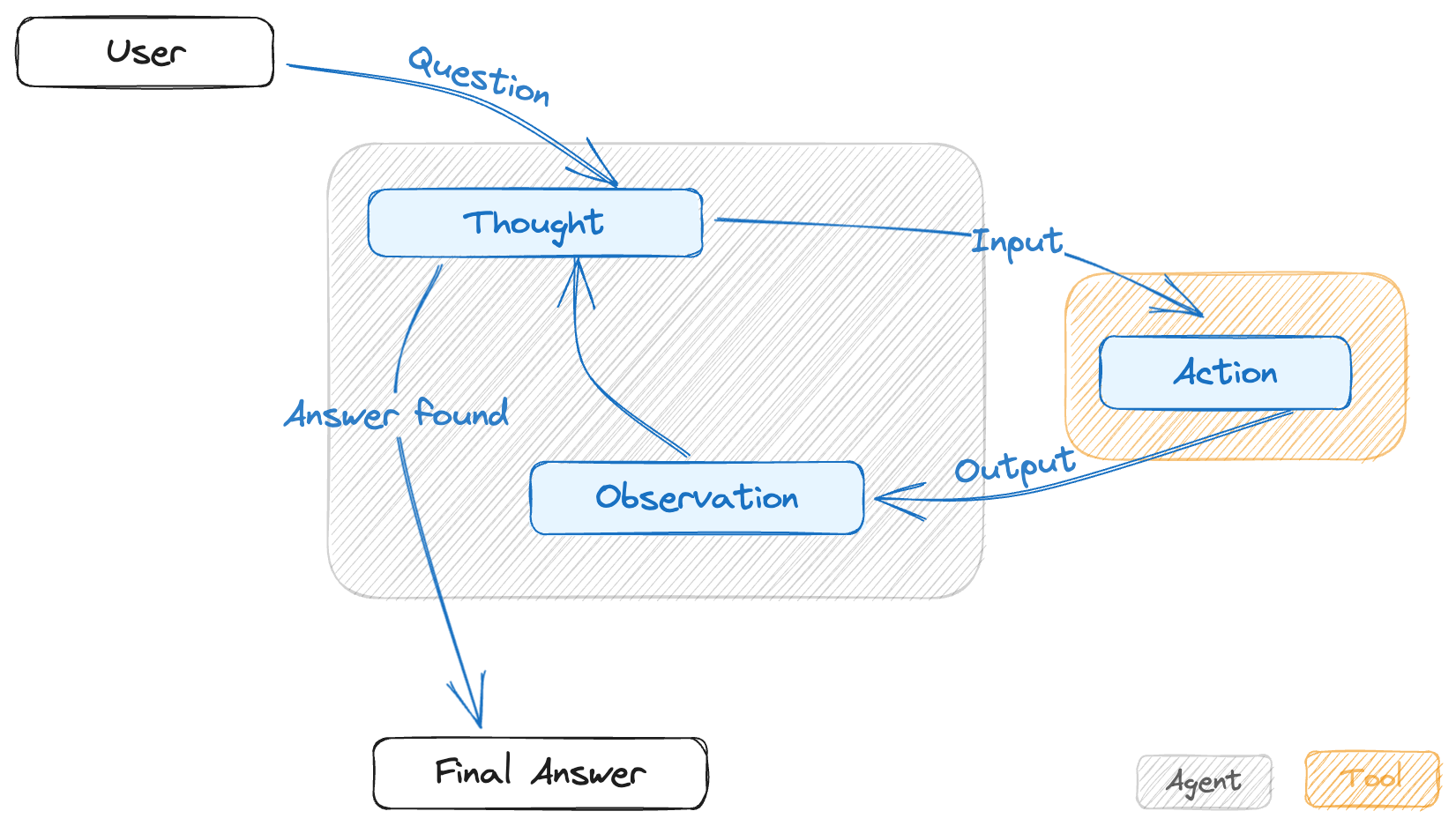
Figura 1 - Workflow semplificato per gli agenti di tipo "Zero-shot ReAct"
Un aspetto particolarmente rilevante da tenere in considerazione è relativo al fatto che gli agenti di questo tipo non hanno memoria e discriminano le loro azioni unicamente sulla base del testo in input e della descrizione del tool. E’ dunque importante che i tool includano anche una descrizione efficace ai fini di una corretta interpretazione da parte del LLM.
Per semplicità, i tool di LangChain sono talvolta raggruppati in gruppi denominati “Toolkits”. Nella documentazione ufficiale troverete un toolkit predefinito che si chiama “SQLDatabaseToolkit”, per configurare appunto un agente SQL.
La descrizione dello scenario
Come preannunciato all’inizio dell’articolo, vogliamo fare una vera e propria analisi in maniera automatica sui dati presenti in un DB relazionale, supponendo di non avere alcuna conoscenza del modello dati né tantomeno competenze SQL. Il punto di partenza sarà infatti un prompt testuale in lingua naturale.
Da un punto di vista tecnico, l’esercizio è facilissimo perché, oltre al toolkit, LangChain mette a disposizione un metodo di utility per la definizione di un SqlAgent in cui dobbiamo passare solo alcuni parametri come i puntamenti al DB, il tipo di LLM, etc..
A prima vista, gli esempi riportati nella documentazione ufficiale sembrano già molto interessanti. Oltre ai casi banali (es: DESCRIBE di una tabella), viene infatti mostrato come l’agente sia in grado di fare inferenza sui metadati per capire come aggregare i dati o mettere in JOIN 2 o più tabelle. Tutto ciò in totale autonomia.
Per non ripetere lo stesso identico esempio presente nella documentazione ed introdurre qualche complicazione in più, decido di creare una versione potenziata del toolkit standard, che sia in grado di fare anche ricerche su Google.
Il dataset
La documentazione ufficiale include degli esempi che fanno uso di un DB di prova basato su SqlLite e denominato “Chinook”, che simula un media store e che trovate anche nel sito ufficiale di SqlLite.
Dando un occhio al modello dati e ai dati stessi, ho guardato con sospetto gli entusiasmanti risultati che hanno riportato, perché il DB è a mio avviso non è rappresentativo di un caso reale:
- i nomi delle tabelle e delle colonne sono tutti abbastanza parlanti ed in lingua inglese, inoltre non viene fatto uso di una naming convention
- il DB sembra praticamente in terza forma normale: improbabile laddove si voglia fare pura analisi dati
- file .db SqlLite in locale? Si tratta di un caso molto lontano dalla realtà!
Fortunatamente ho a disposizione un DB Athena su un mio account AWS con alcune strutture dati più vicine ad un caso reale e di cui conosco un po’ la semantica del dato. Si tratta di OpenData del Comune di Milano, relativi ai transiti all’interno dei varchi di AreaC. In realtà Athena non è un vero DB, quanto piuttosto un SQL-Engine basato su Presto, ma con le opportune configurazioni, AWS mette a disposizione un endpoint che permette di accedervi come se fosse un vero DBMS.
Il Data Model è semplicissimo: si tratta di 2 tabelle dei fatti, che fanno riferimento al conteggio degli ingressi (dettaglio+aggregato), legate entrambe ad una tabella di decodifica dei varchi, in cui sono indicati alcuni attributi tra cui la posizione geografica esatta del varco. In tutti e 3 i casi, si tratta di tabelle Iceberg memorizzate su S3 e mappate su Athena tramite il catalogo di Glue.
I dataset originari li trovate sul portale OpenData ufficiale. Si tratta di circa 4 anni di dati (circa 101 milioni di record nella tabella di cardinalità massima).
Di seguito le DDL delle tabelle con qualche commento che ho aggiunto qui per semplicità (e che dunque l’agente non aveva a disposizione…).
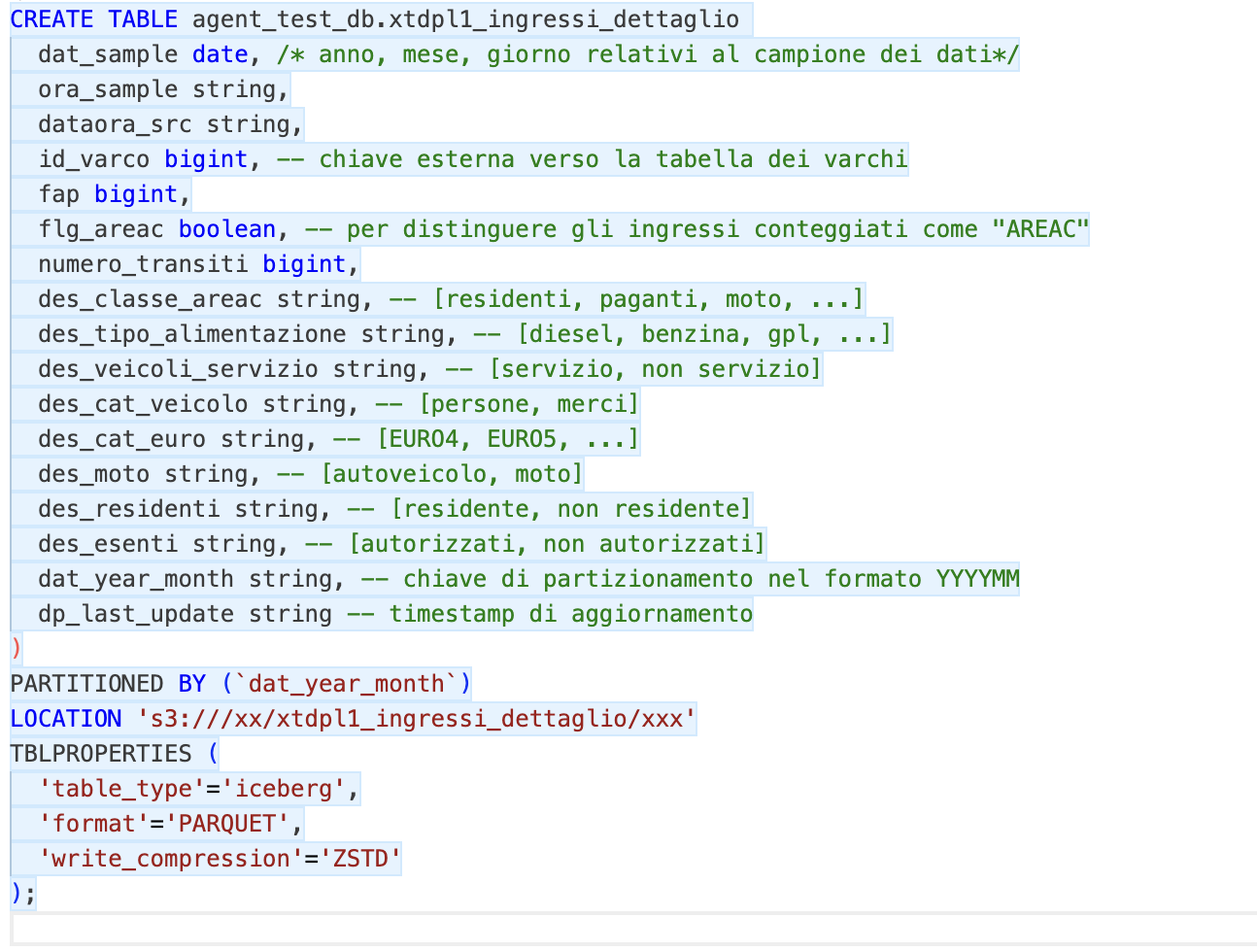
Figura 2 - DDL tabella di dettaglio
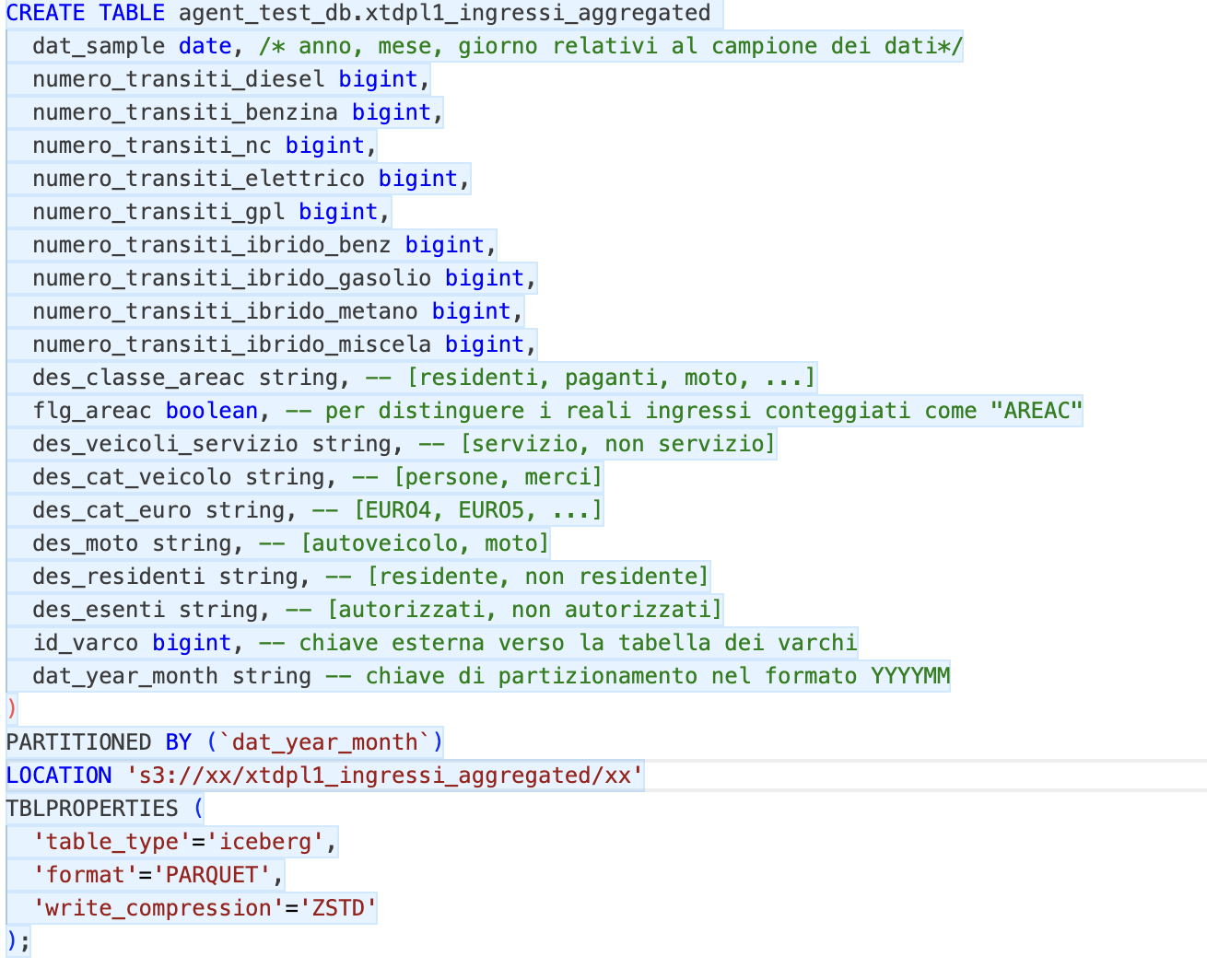
Figura 3 - DDL tabella aggregata
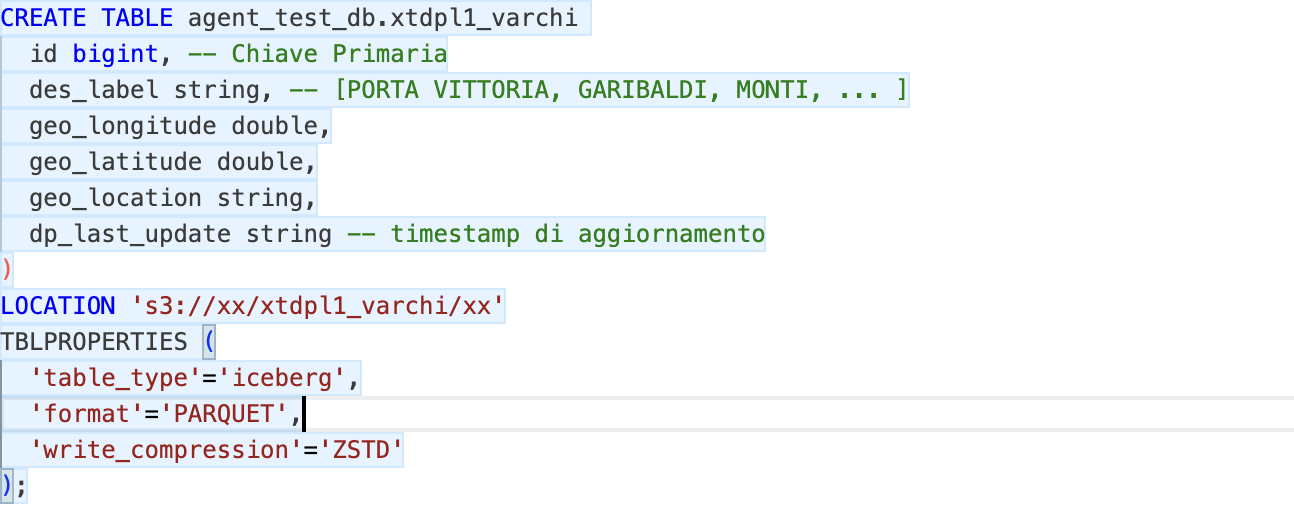
Figura 2 - DDL tabella di decodifica dei varchi
Nella tabella aggregata, oltre a rimuovere qualche attributo, ho fatto una sorta di pivot sul tipo di alimentazione, calcolando i diversi transiti in COLONNA anziché in RIGA, riducendo la cardinalità di circa il 92%. A parte questo, le 2 tabelle dei fatti sono praticamente identiche.
La tabella di decodifica dei varchi, oltre al nome descrittivo, contiene anche le coordinate geografiche.
Come si può vedere, ho usato una naming convention, ma essa è volutamente imperfetta, ad esempio è un mix di inglese ed italiano.
La configurazione software
Riporto di seguito gli import e le configurazioni di base del codice python:
from langchain.agents import create_sql_agent
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents.agent_types import AgentType
import os
from urllib.parse import quote_plus
from ExtendedSqlDatabaseToolkit import *
# carico le variabili di ambiente
from dotenv import load_dotenv
load_dotenv()
# connection string
conn_str = (
"awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@"
"athena.{region_name}.amazonaws.com:443/"
"{schema_name}?s3_staging_dir={s3_staging_dir}&work_group={wg}"
)
# inizializzazione del DB
db = SQLDatabase.from_uri(conn_str.format(
aws_access_key_id=quote_plus(os.environ['AWS_AK']),
aws_secret_access_key=quote_plus(os.environ['AWS_SAK']),
region_name=os.environ['AWS_REGION'],
schema_name=os.environ['AWS_ATHENA_SCHEMA'],
s3_staging_dir=quote_plus(os.environ['AWS_S3_OUT']),
wg=os.environ['AWS_ATHENA_WG']
)
, include_tables=['xtdpl1_ingressi_detailed', 'xtdpl1_ingressi_aggregated', 'xtdpl1_varchi']
, sample_rows_in_table_info=2)
# definizione del toolkit tramite classe Custom
toolkit = ExtendedSqlDatabaseToolkit(db=db, llm=OpenAI(temperature=0))
# inizializzazione dell'Agent
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)LangChain utilizza SQLAlchemy quindi garantisce già l’accesso a un gran numero di DBMS senza la necessità di inventarsi nulla.
Da notare che oltre alle variabili di ambiente relative ad AWS ed esplicitamente referenziate sopra, occorre anche settare le variabili:
- OPENAI_API_KEY: associata all’account OpenAI, essenziale per l’utilizzo del LLM
- SERPAPI_API_KEY: associata all’account SerpApi, al fine di fare programmaticamente ricerche su Google. Esiste una versione FREE che supporta un numero di chiamate mensili < 100
Le opzioni indicate in riga 29 e 30 servono per limitare il raggio d’azione dell’agente ed evitare che faccia ragionamenti troppo estesi su tutto il catalogo o su un sample di dati troppo ampio. Il rischio è infatti quello di saturare molto facilmente i token disponibili dal LLM.
Il toolkit istanziato in riga 34 è una mia classe custom, che estende il SQLToolkit standard messo a disposizione da LangChain. Trattandosi di poche righe di codice, aggiungo anche questo:
"""Enhanced Toolkit for interacting with SQL databases and search over the internet"""
from typing import List
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.tools import BaseTool
from langchain.agents import load_tools
class ExtendedSqlDatabaseToolkit(SQLDatabaseToolkit):
"""Enhanced Toolkit for interacting with SQL databases and search over the internet"""
def get_tools(self) -> List[BaseTool]:
sqlTools = super().get_tools()
additionalTools = load_tools(["serpapi"], llm=self.llm)
return additionalTools+sqlToolsOltre alle librerie esplicitamente referenziate, occorre anche installare le librerie “openai” e “pyathena”.
Le challenges
Ho sottoposto all’agente diverse domande, cercando di stressare le diverse componenti (es: capacità di individuare la semantica del dato, capire cosa cercare su google, quando/se andare nella tabella di dettaglio, etc etc).
Mi limiterò nel seguito a descrivere un paio di esempi, ma prima faccio qualche considerazione generale.
Il modello standard utilizzato dalle librerie OpenAI è Text-davinci-003. Questo modello, è molto più ampio e più costoso (circa 10 volte di più!) di quello usato da ChatGPT (GPT-3.5-Turbo). Esiste molta letteratura che descrive l’efficacia di entrambi e di come il secondo, pur essendo sulla carta più piccolo (6 vs 175 miliardi di parametri), possa comunque avere risultati uguali o in alcuni casi addirittura migliori.
Personalmente ho usato quasi esclusivamente il primo dei 2 e le poche prove che ho fatto con GPT-3.5-Turbo hanno avuto risultati nettamente peggiori, ma non ho approfondito molto questo aspetto, a cui magari dedicherò un altro articolo.
Caso A - Calcolo di un semplice KPI
trova le coordinate e il nome descrittivo del varco in cui ci sono più transiti di veicoli diesel nel periodo di Agosto 2020. Considera gli ingressi effettivamente areac ed escludi i mezzi di servizio
L’output restituito è indicato in Figura 3 e se date un occhio alle righe che iniziano per “Action”, “Observation” e “Thought”, vedrete che esso rispetta quanto previsto nel modello “Zero-shot ReAct”.
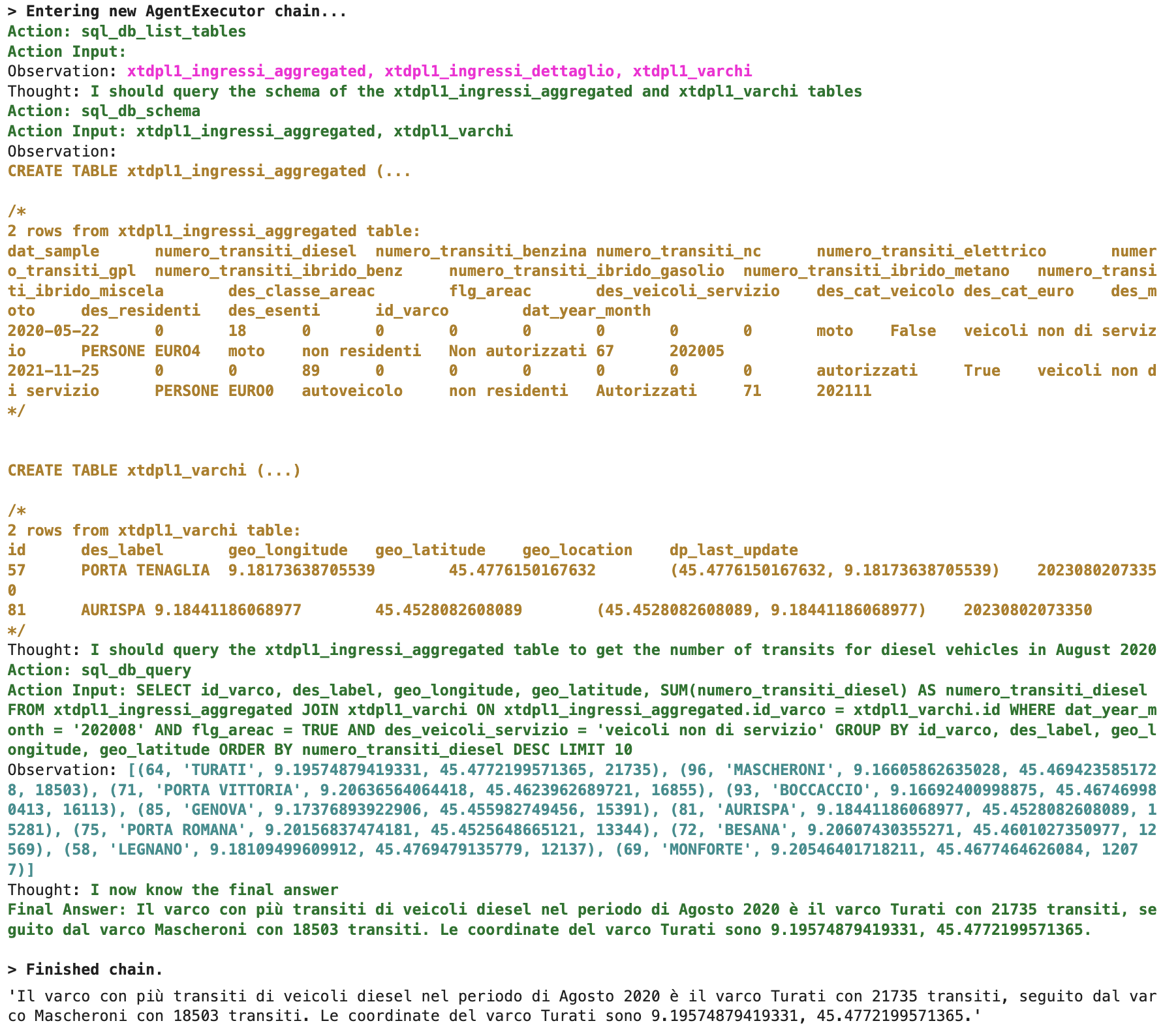
Figura 3 - Output caso A
In particolare, l’agente parte con l’identificazione della Action (sql_db_list_tables) e dell’input (nessun in input in questo caso), ottenendo (Observation) le 3 tabelle su cui abbiamo programmaticamente ristretto la sua visibilità. In teoria il tool potrebbe esplorare tutto il catalogo ma, come anticipato sopra, ho voluto restringere il campo per evitare di saturare i token messi a disposizione del modello.
A questo punto l’agente passa il controllo al LLM (Thought) per decidere la prossima azione e tramite esso determina che le uniche 2 tabelle di interesse sono la tabella dei fatti aggregata e la tabella di decodifica dei varchi.
E’ interessante che già in questa fase abbia dedotto che sia meglio fare la query sulla tabella aggregata rispetto a quella di dettaglio, ma mi stranisce un po’ il fatto che abbia fatto questa deduzione basandosi unicamente sulla naming della tabella, poiché l’inferenza sui metadati e sui dati viene fatta solo in un momento successivo. In tal senso, il risultato finale potrebbe non essere quello corretto qualora le 2 tabelle avessero avuto un perimetro dati diverso (ad esempio qualora la tabella aggregata contenesse solo l’ultimo anno).
Dopo aver letto i metadati e fatto un carotaggio dei dati, il LLM costruisce la query. In questo caso specifico si vede chiaramente che il modello indovina la sintassi della query al primo tentativo, ma ho sperimentato diversi casi in cui esso va a tentativi, correggendo di volta in volta la sintassi fino ad arrivare alla query definitiva (vedi casi B e C).
Il resto è autodescritto nell’immagine.
Un paio di commenti:
- il modello è riuscito a implementare perfettamente i filtri che avevo in mente nel prompt, tramite inferenza sulla naming e/o sui dati
- ho fatto altri tentativi rimuovendo la tabella aggregata e lasciando solo quella di dettaglio e ho ottenuto lo stesso risultato. Da notare però che la tabella di dettaglio ha il KPI in riga anziché in colonna, dunque in quel caso il modello ha capito che andava applicato il filtro “des_tipo_alimentazione = ‘diesel’”
- come da attese, non è stata fatta alcuna ricerca su google, perché ovviamente non serviva
Caso B - informazioni aggiuntive
trova il varco in cui ci sono più transiti di veicoli diesel nel periodo di Agosto 2020, includendo solo ingressi areac ed escludendo i mezzi di servizio. Restituiscimi anche i 3 varchi più vicini ad esso
Qui, il LLM mi ha sorpreso: ho aggiunto la frase finale per costringerlo a fare una ricerca su Google, ma non avevo pensato che partendo dalle coordinate geografiche fosse possibile calcolare la distanza con delle operazioni matematiche, dunque il tool (e cioè il modello LLM sottostante) ha eseguito l’intero task all’interno del DB tramite le funzioni ST_POINT ed ST_DISTANCE come mostrato in Figura 8.
Ho omesso la prima parte dell’output perché identica al caso precedente.

Figura 4 - Output caso B
Come si vede dai vari messaggi di errore, in questo caso il modello ha avuto diverse “allucinazioni” nella costruzione della query SQL, ma è riuscito a correggerli fino ad arrivare alla query definitiva perché l’agente ha restituito al modello LLM i feedback di tali errori tramite i loop Action-Observation-Thought.
Caso C - esecuzione combinata SQL+Ricerca
L’estrema semplicità del modello dati non mi ha aiutato molto nel creare una richiesta sufficientemente articolata, dunque ho dovuto fare un po’ di prompt engineering per costringerlo a fare una ricerca sul web. Alla fine sono riuscito ad ottenere qualcosa con una richiesta di questo tipo:
trova le coordinate e il nome descrittivo del varco in cui ci sono più transiti di veicoli diesel nel mese di Agosto 2020. Cerca la fermata dei mezzi pubblici più vicina a quel varco
Qui sono accadute 2 cose strane:
- nonostante la prima parte del prompt fosse quasi identica al caso A (ho usato “nel mese di” anziché “nel periodo di”), il LLM esegue l’operazione di MAX anziché di SUM
- come da attese, l’agente ha eseguito la ricerca tramite SerpApi per individuare la fermata dei mezzi ma, anziché usare le coordinate, ha usato il nome descrittivo del varco. Il risultato chiaramente non è in linea con le aspettative, perché viene restituita una fermata dei mezzi della città di Venezia

Figura 4 - Output caso C
Conclusioni
Come già ho scritto nel precedente articolo, la curva di apprendimento per adottare LangChain è piuttosto bassa. Bastano poche righe di codice per ottenere un effetto “wow” e consentire a chiunque di implementare una propria soluzione custom, magari integrata con il resto dell’ecosistema aziendale (repository documentali, Data APIs, mail server, shared file systems, …) e/o con il proprio LLM (ad esempio, è possibile integrare una propria installazione di Llama 2 on-premise) laddove non si vogliano condividere dati al di fuori dell’organizzazione aziendale.
D’altro canto, gli esempi che ho riportato sopra sono da considerarsi come tutorial semplificati per prendere dimestichezza con il framework.
Per mettere a terra delle soluzioni reali, serve un approccio più strutturato, che sfrutti meglio le caratteristiche del framework e tenga conto delle peculiarità dei modelli.
Ad esempio, mi sono reso conto che non è stata una scelta saggia quella di unire le funzionalità SQL e di ricerca SerpApi in un unico toolkit e che sarebbe stato meglio integrare le 2 funzionalità tramite agent/chain separati.
Come altro esempio, ho notato che nel pacchetto “experimental” è presente una classe che si chiama “SQLDatabaseChain” che con poche righe di codice permette di sviluppare un Tool Sql from scratch, bypassando completamente il toolkit standard:
sql_chain = SQLDatabaseChain.from_llm(llm=llm, db=db, verbose=True)
sql_tool = Tool(
name='Areac DB',
func=sql_chain.run,
description="Database che contiene i dati relativi agli ingressi nei varchi dell'area C di Milano."
" Le tabelle principali sono xtdpl1_ingressi_aggregated e xtdpl1_varchi."
" La tabella xtdpl1_ingressi_aggregated contiene le principali misure, come ad esempio il conteggio del numero di accessi per ciascuno dei varchi e per ciascun giorno dell'anno."
" Il campo relativo alla dimensione tempo si chiama dat_year_month ed è di tipo numerico, nel classico formato YYYYMM."
" Il campo flg_areac è di tipo BOOLEAN (true/false) ed indica se si tratta di un ingresso effettivamente conteggiato come areac."
" La tabella xtdpl1_varchi contiene la decodifica dei varchi. La chiave principale di questa tabella è il campo 'id', che identifica il varco. Gli altri attributi sono descrittivi."
)Poiché l’agente utilizza il LLM per decidere QUALE tool utilizzare e COME utilizzarlo unicamente in base alla descrizione del tool, questo approccio ha il grande vantaggio di migliorare le performance semplicemente aggiungendo una descrizione efficace del DB all’interno del tool, senza modificare in alcun modo il modello LLM. Nel mio caso, ad esempio, ho aggiunto incrementalmente un gran numero di dettagli e ho notato un progressivo miglioramento delle performance.