Langchain pt. 3 - How to call Rest API in natural language
Intro
Last year, Gartner put Generative AI at the peak of inflated expectations in its AI Hype Cycle.
Recently, big tech leaders compared the hype around GenAI to the dotcom bubble. Furthermore, according to some rumors, the main Cloud Providers are even giving instructions to their Sales Teams to slow down the enthusiasm towards customers regarding GenAI initiatives and promoting cost-vs-benefits awareness. Has the drop into the trough of disillusionment already begun?
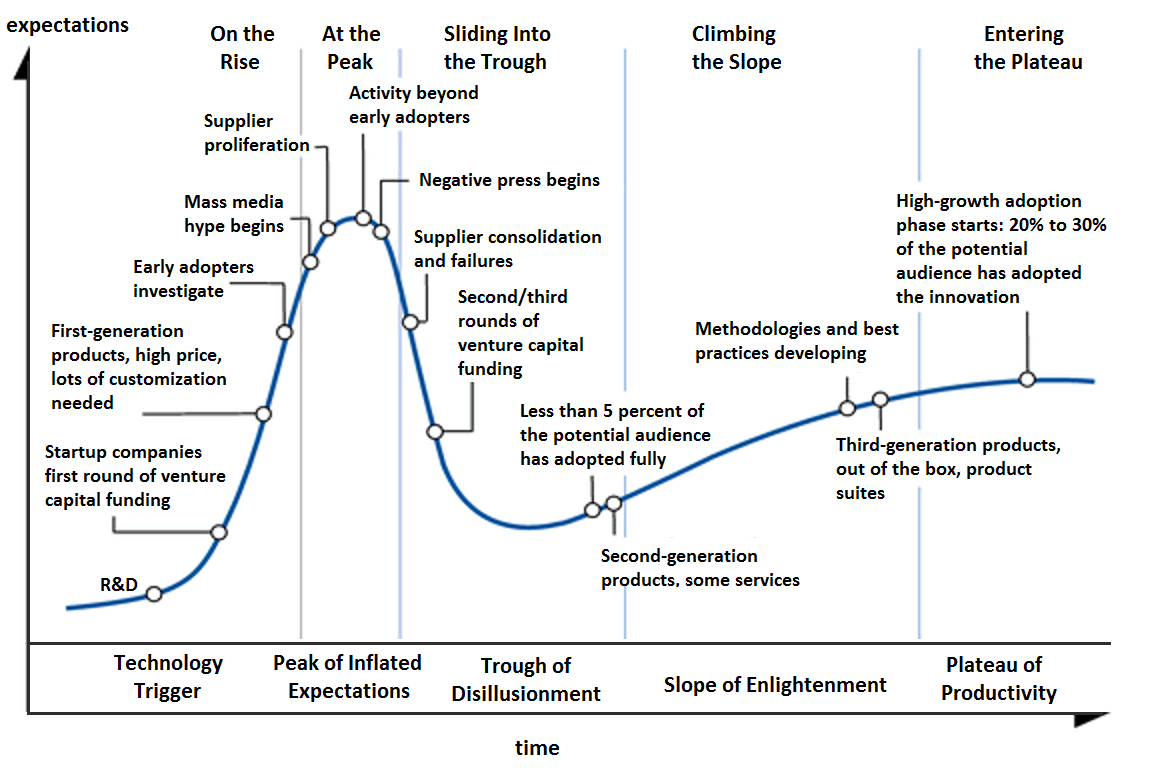
Maybe the classic Hype Cycle model is not applicable this time. Compared to other transformative and technological trends, we are moving very quickly towards a phase of awareness and maturity. The market is moving beyond the race for the most powerful model in terms of “brute force” and new market trends arise:
- Many vendors are working on relatively small models that can also be run locally, for example:
- Meta and Qualcomm have recently accounced a collaboration aimed to optimize the Llama3 models in order to make them executed directly on devices equipped with future top-of-the-range Snapdragon platforms
- H2O launched a super tiny language model called Danube, which is a fork from Llama2 designed to be to be executed on mobile devices
- Rumors on Apple reported that they are working on a “on-device” language model which will also be available offline
- All the big players in the AI market are introducing multi-modal products
- Several frameworks are emerging for designing modular solutions, using LLM models as building blocks to build complex and vendor-agnostic “AI-powered” applications
- In other words, to draw a parallel with what happened many years ago with the birth of software engineering, these products are paving the way for “AI Engineering”
LangChain is going precisely in this direction. It’s one of the most complete and powerful AI Open Source frameworks at the moment. It provides great control and flexibility for various use cases and offers greater granularity than other frameworks such as, for example, LlamaIndex. One of the features I have tested in recent days is the Rest-API integration, using well-defined standard specifications (e.g. Swagger, OpenApi) or even described in natural language.
In this article, I will show how to integrate a third-party API “at runtime” into a very simple chatbot, and query the API in natural language without any prior knowledge about the API specifications.
Technical preamble
The code shown below, available on GitHub is making use of OpenAI and Bedrock. The latter, for those who don’t know it, is the AWS service that gives access to various models including Llama2, Claude, Mistral and the AWS proprietary model called Titan. The code is extremely simple and can be summarized as the following logical steps:
- Environment variable settings
- LLM initialization
- API specifications dynamic retrieval
- Setup and invoke of the APIChain component. This component applies some simple Prompt Engineering techniques to perform the following 3 actions:
- Take the user’s question in natural language as input and construct, via the LLM, the URL to be invoked
- Invoke the URL thus built via an HTTP call
- Wrap the response obtained from the HTTP call into a new LLM invocation and obtain the information requested by the user in terms of natural language.
The overall process is summarized into the following flow diagram:
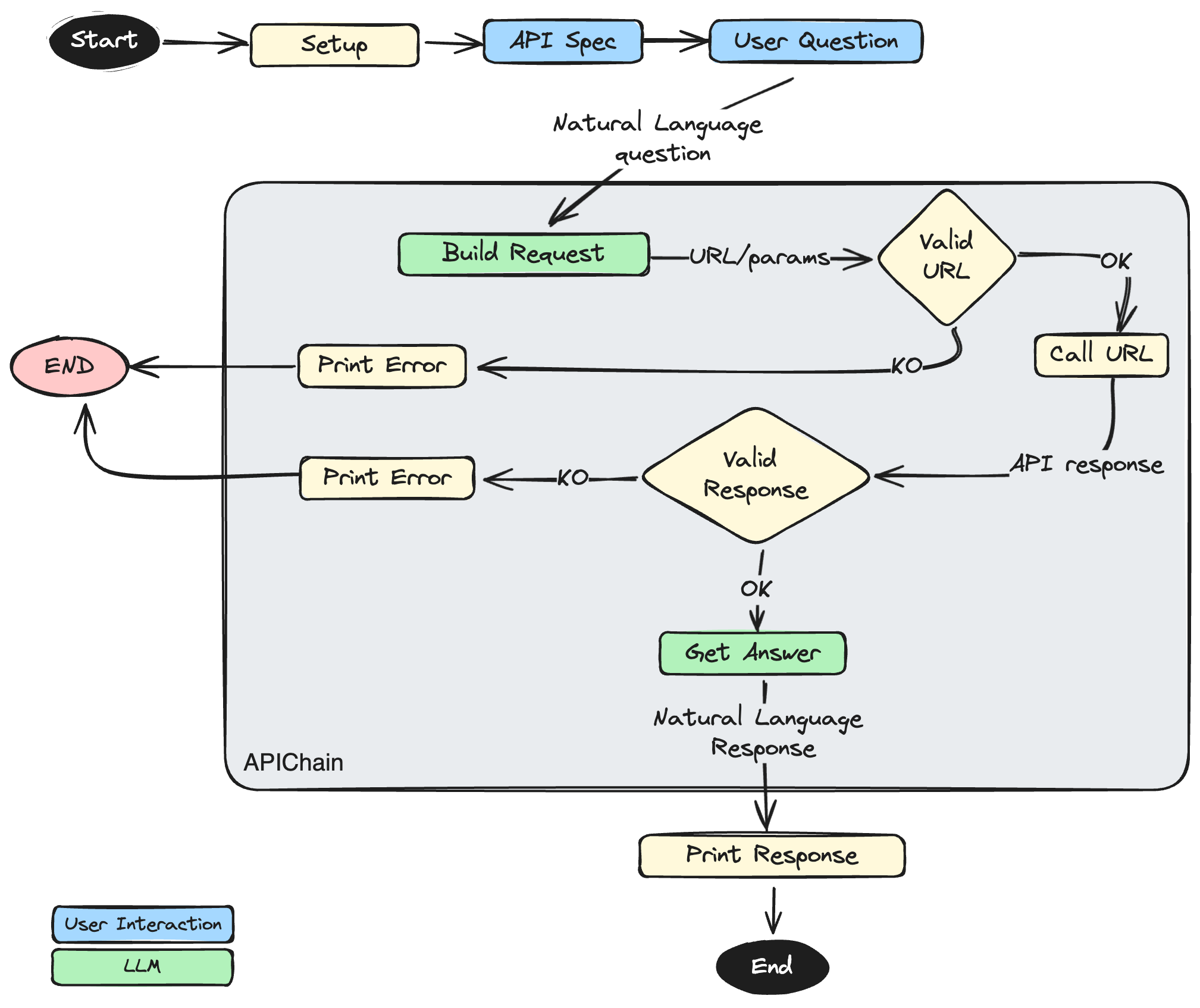
For sake of simplicity, in the code that follows I have hard-coded the user interactions parts, but it’s easy to obtain these inputs dynamically via a dialogic user interation in a Chatbot application. In such a scenario, you could also configure the APIs specifications using a well-defined administration interface and then plug&play directly the API into the chatbot to add features at-runtime.
In other words, with very small effort, you can build a chatbot that is completely agnostic with respect to the API specifications and dynamically adapts to the user needs, adding references to new APIs on the fly.
As real use case, you can imagine a customer care tool that integrates with company APIs to directly return information related to the customer orders, products, reports, etc.. You can thus develop these features incrementally, while enhancing the capabilities exposed by the chatbot and use a plug&play approach, adding new APIs within the existing dialogic process.
Broadening the discussion and moving towards a more Enterprise context, we can imagine the scenario of a modern Data Platform that makes the company KPIs available in the form of Data-APIs thus allowing anyone in the company accessing such KPIs via the enterprise chatbot.
The APIs
The APIs I’ve used to test are the following:
- klarna.com
- for those who don’t know the brand, Klarna is a Swedish fintech that offers payment processing services for the e-commerce industry. Klarma payment options are usually available on most common online shopping websites. The Klarna API can be accessed for free and allows searching for products based on text description, price, brand, etc.. It is only available in a few countries (US, GB, DE, SE, DK).
- open-meteo
- It’s a free API that makes meteorological data available. The most common use case is when we query the API to obtain the weather conditions in a certain city, in terms of temperature, precipitation, visibility, etc.
APIChain
The main component we are going to use within the LangChain suite is called APIChain. Under the hood, the chain is made of:
- An instance of an LLMChain, which is used to build the URL and the HTTP parameters from the natural language question
- A wrapper of the request component, which is used to send the HTTP request
- An instance of an LLMChain that is used to build the response in natural language, starting from the raw HTTP Response payload
- Some pre-built prompts that are used to prepare the context and effectively implement invocations of the LLM
As regards the prompts that the APIChain component makes available, during the tests I realized that they did not work correctly with all LLMs (for example: they worked with OpenAI, but not with Llama2, Claude, etc). Therefore, I’ve built a slightly better version of such prompts and proposed the change on the official repo (we’ll see if they accept it 😃 ).
The test
You can find the full source code in the GitHub repository.
In the first part of the code I’ve initialized the basic components and created the models.
Some notes:
- The environment variables related to integration with OPEN_AI and AWS must be configured in the .env file
- I’ve created a wrapper for instantiating the LLM model (see the “libs.py” file)
- Some of the involved AWS services are currently only available in some Regions. Therefore you need to pay attention to the region settings and the costs associated with use
from langchain.chains import APIChain
from dotenv import load_dotenv
import httpx
import logging as logger
import sys
# see "libs.py" file
from libs import *
# see "prompt_improved.py" file
from prompt_improved import *
# Set WARNING Logger levels help print only meaningful text
logger.basicConfig(stream=sys.stdout, level=logger.WARNING)
logger.getLogger('botocore').setLevel(logger.WARNING)
logger.getLogger('httpx').setLevel(logger.WARNING)
# loading ENV variables
load_dotenv()
# Initialize Models
gpt35 = create_llm(model={"provider":"OpenAI", "value": "gpt-3.5-turbo"}, model_kwargs={"temperature": 0.1})
gpt4 = create_llm(model={"provider":"OpenAI", "value": "gpt-4"}, model_kwargs={"temperature": 0.1})
claude3 = create_llm(model={"provider":"Anthropic", "value": "anthropic.claude-3-sonnet-20240229-v1:0"}, model_kwargs={"temperature": 0.1})
llama2 = create_llm(model={"provider":"Meta", "value": "meta.llama2-70b-chat-v1"}, model_kwargs=None)Ok, now let’s see how to dynamically integrate the interface descriptor and pass it to the APIChain component. The “limit_to_domains” variable is used to introduce a security mechanism that limits the domains to which requests can be directed. You could also set it to “None” to remove such constraints (not recommended). The variables api_url_prompt and api_response_prompt allow you to customize the prompts to be passed to the LLM. As I mentioned previously, I’ve set up 2 custom prompts that proved to be more robust than the default ones.
# Dynamically retrieve swagger
output = httpx.get("https://www.klarna.com/us/shopping/public/openai/v0/api-docs/")
swagger = output.text
# build the APIChain
chain = APIChain.from_llm_and_api_docs(
llm=gpt4,
api_docs=swagger,
verbose=False,
limit_to_domains=["klarna.com", "https://www.klarna.com/", "https://www.klarna.com"],
api_url_prompt=FINE_TUNED_API_URL_PROMPT,
api_response_prompt=FINE_TUNED_API_RESPONSE_PROMPT
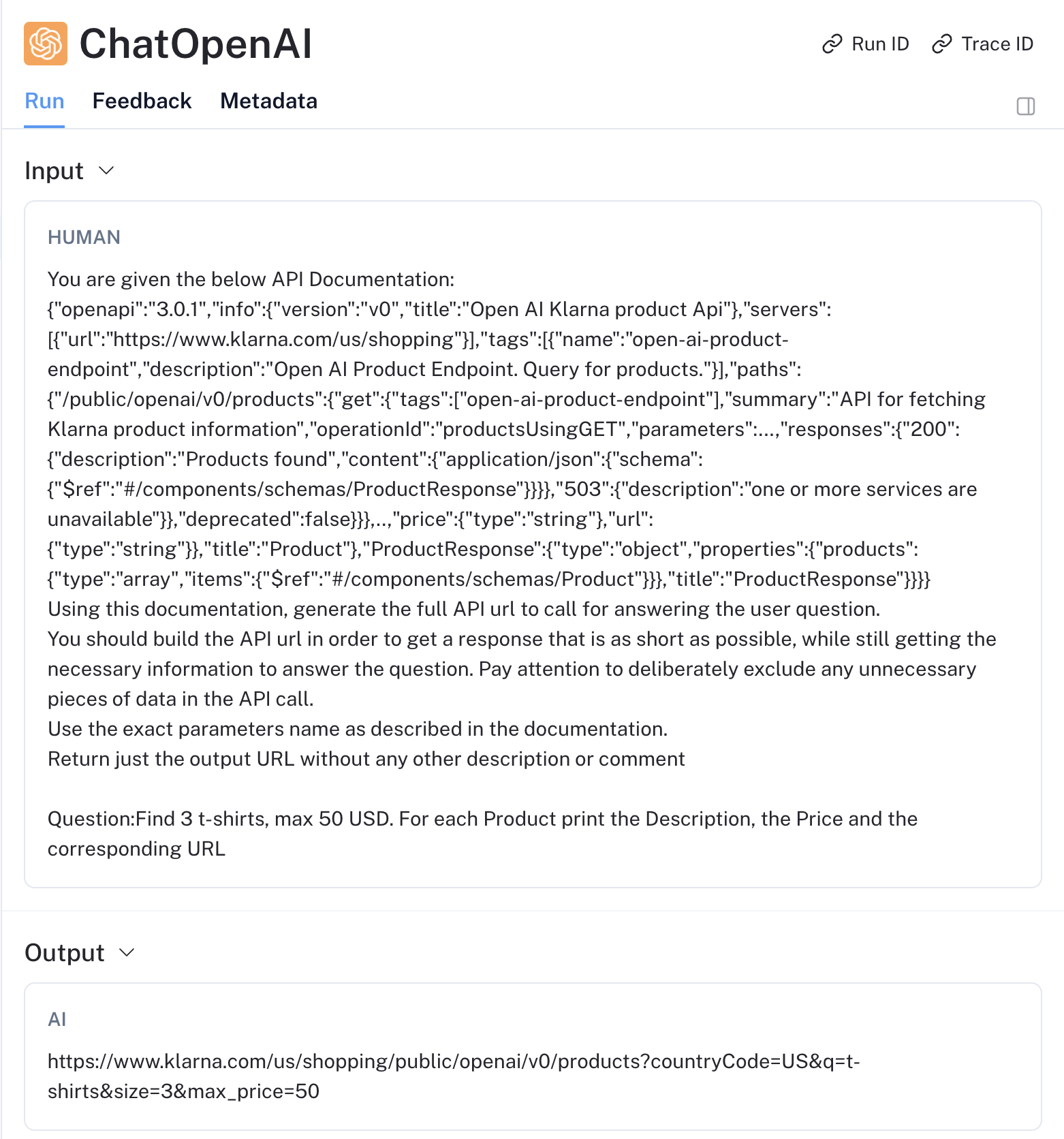
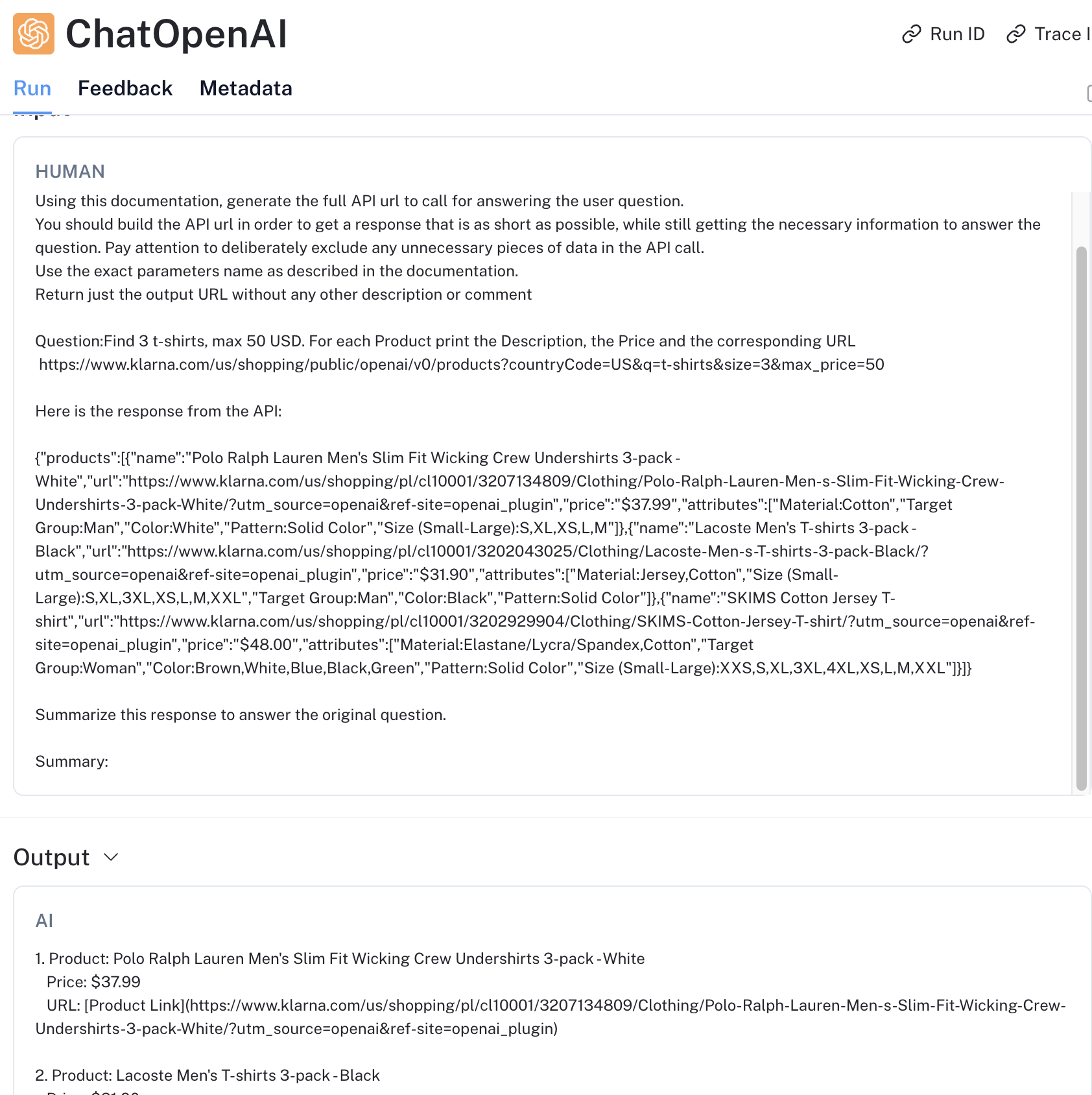
)At this point everything is set. We can ask a question and pass it to the framework and then return the output to the end user. I’ve asked to look for 3 t-shirts with a maximum price of 50 dollars and return price, description and the source link.
# Ask a question to the Chain
response = chain.invoke(
"Find 3 t-shirts, max 50 USD. For each Product print the Description, the Price and the corresponding URL"
)
# Print the Chain Output
print(response['output'])This is the output I got on the first try:
1. *Product: Polo Ralph Lauren Men's Slim Fit Wicking Crew Undershirts 3-pack - White*
*Price: $37.99*
*URL: https://www.klarna.com/us/shopping/pl/cl10001/3207134809/Clothing/Polo-Ralph-Lauren-Men-s-Slim-Fit-Wicking-Crew-Undershirts-3-pack-White/?utm_source=openai&ref-site=openai_plugin*
2. *Product: Lacoste Men's T-shirts 3-pack - Black*
*Price: $31.90*
*URL: https://www.klarna.com/us/shopping/pl/cl10001/3202043025/Clothing/Lacoste-Men-s-T-shirts-3-pack-Black/?utm_source=openai&ref-site=openai_plugin*
3. *Product: SKIMS Cotton Jersey T-shirt*
*Price: $48.00*
*URL: https://www.klarna.com/us/shopping/pl/cl10001/3202929904/Clothing/SKIMS-Cotton-Jersey-T-shirt/?utm_source=openai&ref-site=openai_plugin*Not bad!
I did several other tests with the other models and obtained similar performances although, as I expected, GPT4 and Claude3 are on average more precise.
As for the second API, the code is practically the same. You just have to modify the reference to the URL descriptor (swagger), the limit_to_domains variable which must be consistent with the API and the user’s question. So, I’m omitting the first part of the Python script.
Warning: There is no official swagger for this API, so I’ve used the YAML file I’ve found on GitHub. I have noticed that sometimes HTTP calls to GitHub fail. In that case I suggest to try again a couple of times.
# Dynamically retrieve swagger
output = httpx.get("https://raw.githubusercontent.com/open-meteo/open-meteo/main/openapi.yml")
meteo_swagger = output.text
# build the APIChain
chain = APIChain.from_llm_and_api_docs(
llm=claude3,
api_docs=meteo_swagger,
verbose=True,
limit_to_domains=None,
api_url_prompt=FINE_TUNED_API_URL_PROMPT,
api_response_prompt=FINE_TUNED_API_RESPONSE_PROMPT
)
# Ask a question to the Chain
response = chain.invoke(
"What is the weather like right now in Munich, Germany in degrees Fahrenheit?"
)
# Print the Chain Output
print(response['output'])The output with Claude, GPT 3.5 and GPT4 is good as expected. The 2 Langchain calls have built the URL and processed the response, transforming it into natural language.
The current weather in Munich, Germany is 45.7°F with a wind speed of 17.7 km/h coming from 264° direction.The same test with Llama2 was unsuccessful as it hallucinated the first call, in which LangChain creates the URL, adding some unexpected parameters.
Behind the scenes
Another super interesting tool from the LangChain suite is called LangSmith, which allows you to monitor and profile all model invocations. In addition to this, it allows you to do many other things, such as:
- advanced debugging
- continuous evaluation of the AI application through pre-defined datasets and evaluation criteria
- tracing annotations, in order to collect user feedback within the application
- many other features for monitoring and improving LangChain applications
Using LangSmith, you can see the overall process and the underlying LLM invocations.
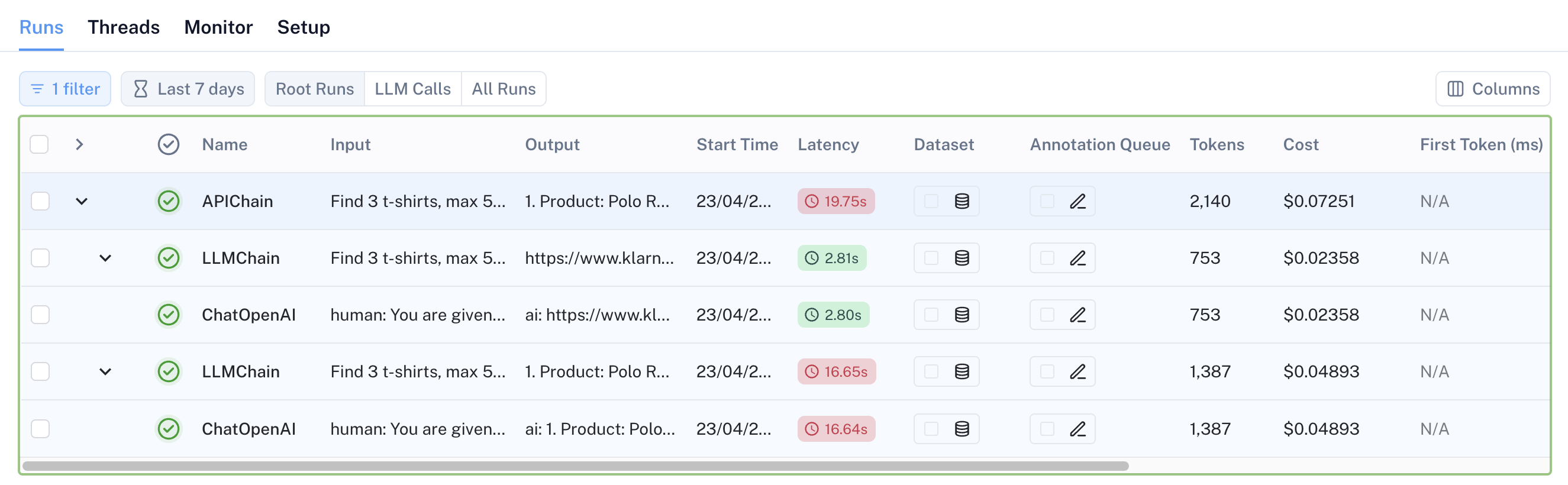
In the image above you can clearly see the invocation tree, identified by the root “APIChain”, which is made of 2 LLM child chains, each one calling the OpenAI Chain. You can also see useful information like the number of used tokens and the estimated cost for each LLM invocation.
If you click on the items, you can also see the actual prompt and the response for each LLM invocation.
Final thoughts
If you take a look at the LangChain source code and LangSmith profiling tools you can clearly see there is no rocket science under the hood, cause it’s mostly implemented through Prompt Engineering techniques. Nevertheless these tecniques allow extremely powerful integration between new AI applications and traditional systems.
In my opinion, it is one of the clearest examples of how today we can (and perhaps we should) review the human/machine interaction in terms of integration between well-specified formal systems with predictable behavior (e.g. any traditional software system in the company) and natural language.
LangChain and other frameworks allow you to do something similar even at a lower level, for example by querying a database in natural language and using an LLM to generate the underlying queries. Even ignoring performance and scalability issues, this approach is good in theory but, based on my experience, there are several practical problems that make me think it is not really applicable but in some specific scenarios, since in most cases you’ll find application layering and poor or missing data catalogs. Conversely, enterprise APIs usually speak a Business-related language and have self-descriptive metadatas.