Langchain pt. 2 - Data Analysis through Agents
Intro
In the previous article I gave a very brief overview of LangChain, describing its main concepts with some examples with unstructured data in pdf format.
Following the same approach, in this article we will give a brief introduction to Agents and proceed by trying to answer an ambitious question:
leveraging these new AI tools, can we carry out data analysis on our DB without any knowledge of SQL nor of the data model, simply starting from a text prompt in natural language?
Agents
LLMs are extremely powerful, but they seem to be completely ineffective in answering questions that require detailed knowledge not tightly integrated into model training. Over the internet there are dozens of examples that manage to catch ChatGPT out through hallucinations or lack of response (eg: weather forecasts, latest news, gossip or even specific mathematical operations).
Frameworks like LangChain can overcome these limitations by defining specific and data-aware components, but usually the actions performed by the framework are predetermined. In other words, the framework uses a Language Model to perform some actions, but they are “hardcoded” and in many cases this can make AI models completely ineffective, because you can’t drive specific actions based on user input.
That’s where agents come into play
Agents are components that have a series of tools available to perform specific actions, such as doing a search on Wikipedia or Google, or executing Python code or even accessing the local file system.
Agents use an LLM to understand user input and decide how to proceed accordingly:
- Which tool among the provided set should be the most appropriate to use?
- What’s the input text to be passed as input to the tool?
- Have we reached the goal thus answering the initial question or should we repeat step 1 and 2 again?
This approach was inspired from a framework called ReAct which has been defined at the end of 2022 by a joint team of researchers from Google and Princeton University. You can find here the original paper. In LangChain, there are several implementations of such approach, but the most common is called “Zero-shot ReAct” and can be described at a high level with the following workflow.
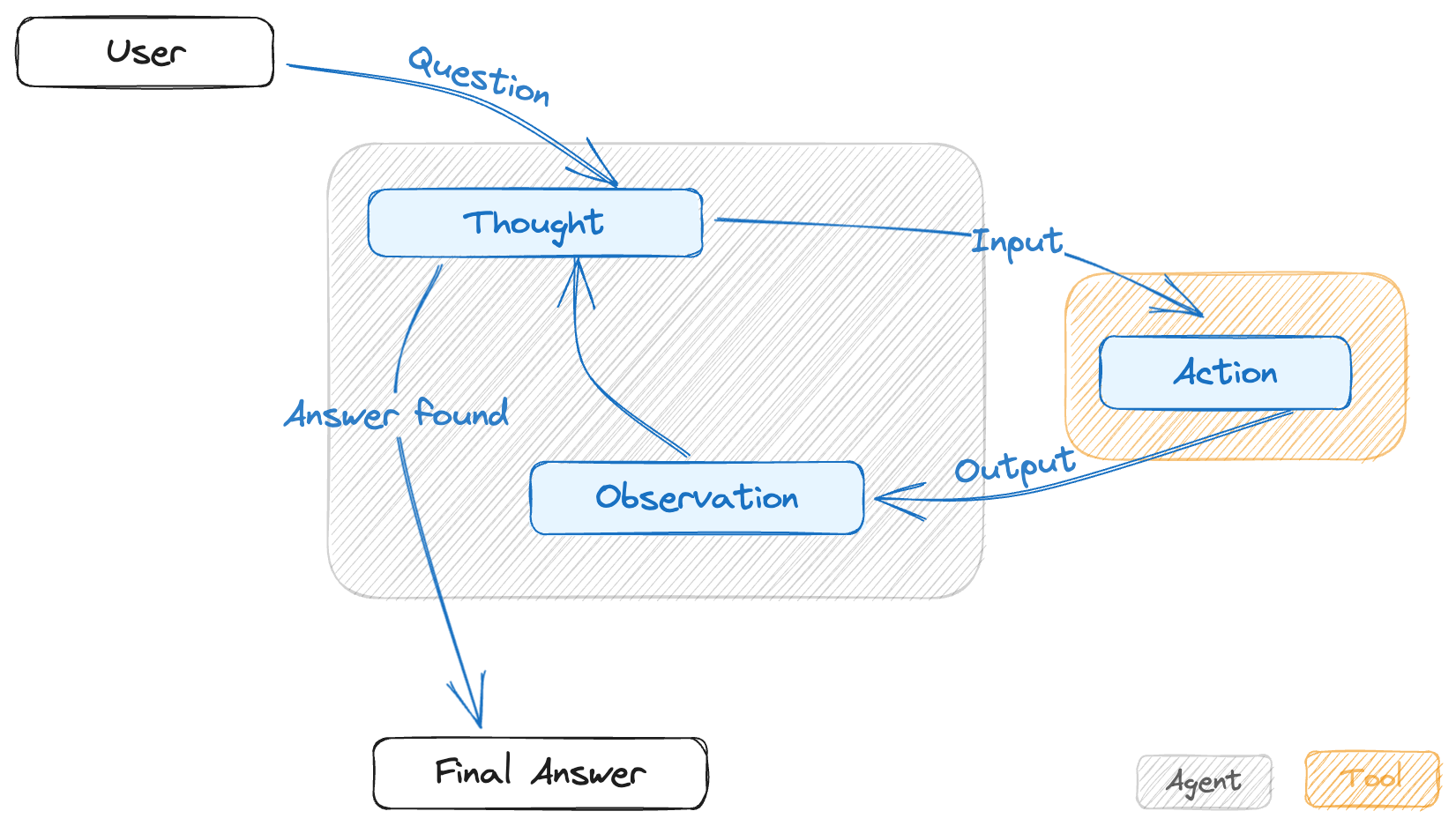
Figure 1 - Simplified workflow for "Zero-shot ReAct" agents
Please note that this type of agents have no memory and so discriminate their actions only on the basis of the input text and the description of the tool. It is therefore very important that the tools also include an effective description for the purpose of a correct interpretation by the LLM.
LangChain tools are sometimes grouped into groups called “Toolkits”. In the official documentation you will find a default toolkit called “SQLDatabaseToolkit”, to configure a SQL agent.
The scenario
As I said at the beginning of the article, we want to do a real analysis on the data present in a relational DB, assuming we have no knowledge of the data model nor SQL skills. The starting point will be a text prompt in natural language.
From a technical standpoint, the task is very easy because, in addition to the toolkit, LangChain provides a utility method for defining a SqlAgent to which we only have to provide some parameters such as the DB connection, the type of LLM, etc..
At first sight the examples given in the official documentation look already very interesting and complete. In addition to trivial use cases (eg DESCRIBE a table), it is shown how the agent is able to make inferences on metadata to understand how to aggregate data or JOIN 2 or more tables.
In order to not repeat the same example taken from the documentation and introduce some more complications, I’ve decided to create an enhanced version of the standard toolkit, which is also able to do searches over the internet.
The dataset
The official documentation includes examples that make use of a test DB based on SqlLite and called “Chinook”, which simulates a media store and which you can also download from the official SqlLite site.
Taking a look at the data model and the data itself, I was suspicious of the exciting results they reported, because the DB is in my opinion not representative of a real case, because:
- the names of the tables and columns are all defined in English and self-describing, moreover no naming convention has been used
- the DB seems practically in 3NF and this is pretty unlikely in scenarios where you want to do pure data analysis
- local SqlLite .db file? This is a case very far from reality!
From past personal projects, I have made available an Athena DB on my AWS account with some data structures that in my opinion are more representative of real use-cases. The data is related to OpenData of the Municipality of Milan, relating to transits within the AreaC gates. AreaC is the the main LTZ (Limited Traffic Zone) for the city of Milan. Actually Athena is not a real DB, but rather a SQL-Engine based on Presto, but with the appropriate configurations, AWS provides an endpoint that allows you to access it as if it were a real DBMS.
The Data Model is very simple: it’s made of 2 fact tables, containing the AreaC crossing events (detail + aggregate), both linked to a decoding table of the entrances, in which some attributes are indicated, including the exact geographical position of the passage. In all 3 cases, these are Iceberg tables stored on S3 and mapped to Athena via the Glue catalog.
The original datasets have been taken from the official OpenData portal. This is about 4 years of data (about 101 million records in the biggest fact table).
Please find below the DDLs of the tables with some comments that I have added here for simplicity (and which therefore the agent did not have available…).
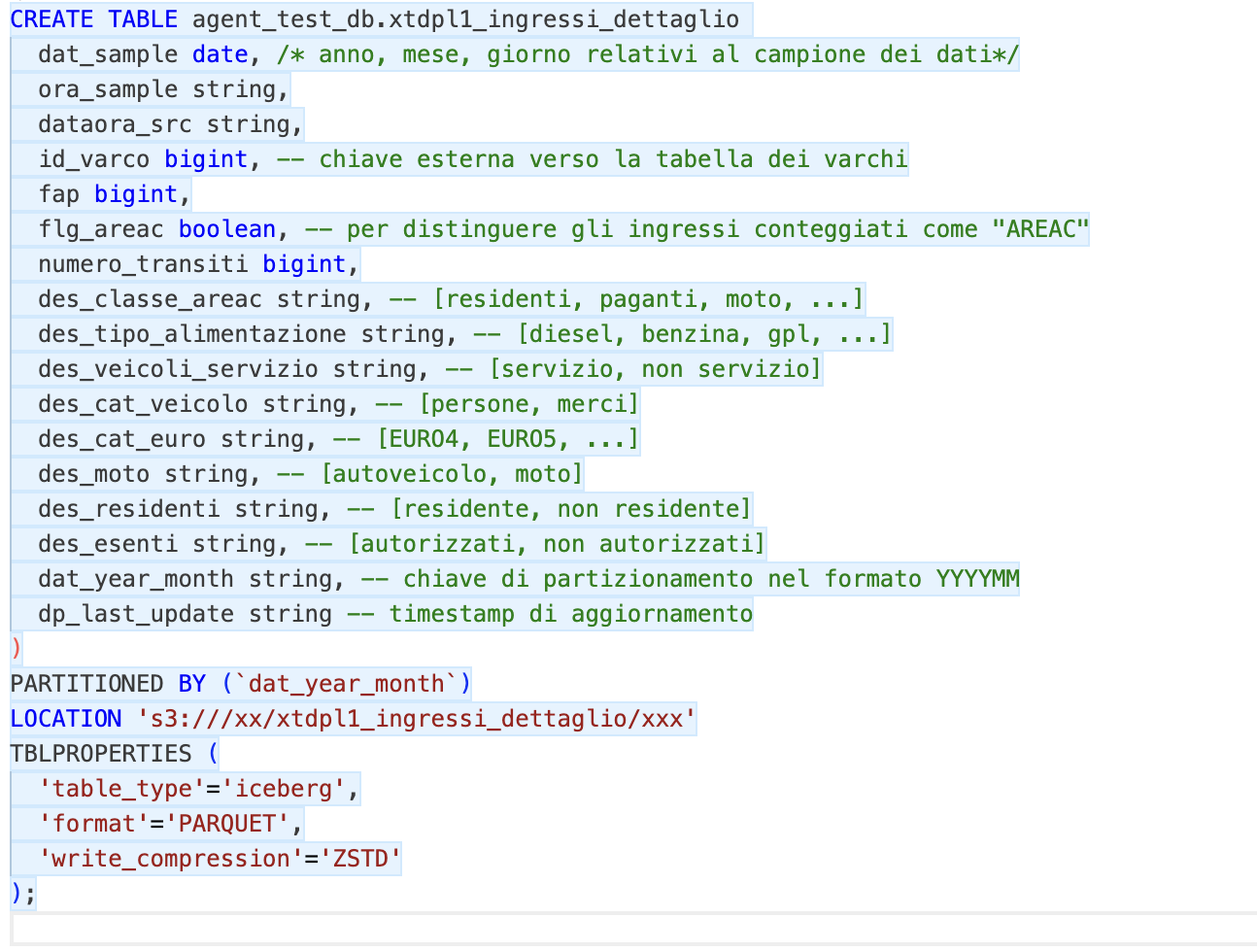
Figure 2 - Detailed fact table DDL
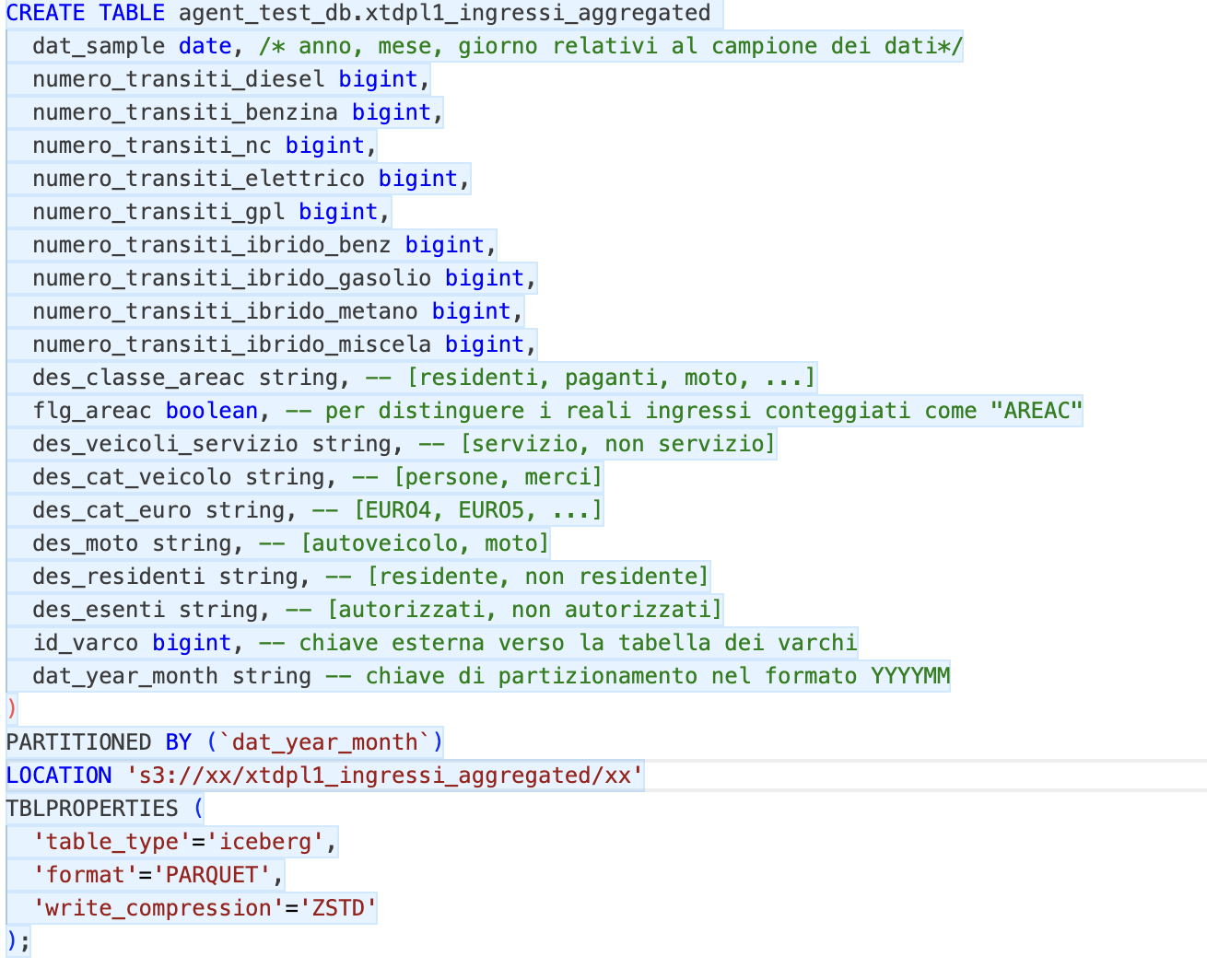
Figure 3 - Aggregated fact table DDL
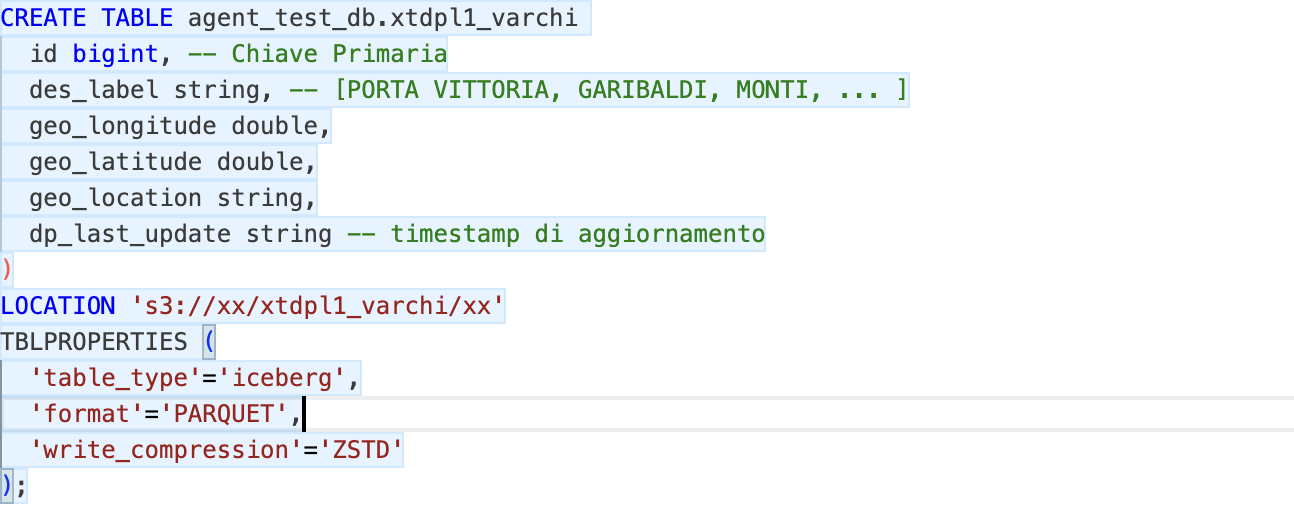
Figure 2 - Gate decoding table DDL
In the aggregate table, in addition to removing some attributes, I’ve made a sort of pivot on the type of power supply, calculating the different transits in COLUMN instead of ROW, reducing the cardinality by about 92%. Other than that, the 2 fact tables are pretty much identical.
The Gate decoding table contains the descriptive name and the geographical coordinates.
As you can see, I’ve used a naming convention, but this is deliberately imperfect, for example it is a mix of English and Italian.
The software setup
Please find below the basic imports and configurations of the main python code:
from langchain.agents import create_sql_agent
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents.agent_types import AgentType
import os
from urllib.parse import quote_plus
from ExtendedSqlDatabaseToolkit import *
# set the environment variables
from dotenv import load_dotenv
load_dotenv()
# connection string
conn_str = (
"awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@"
"athena.{region_name}.amazonaws.com:443/"
"{schema_name}?s3_staging_dir={s3_staging_dir}&work_group={wg}"
)
# database initialization
db = SQLDatabase.from_uri(conn_str.format(
aws_access_key_id=quote_plus(os.environ['AWS_AK']),
aws_secret_access_key=quote_plus(os.environ['AWS_SAK']),
region_name=os.environ['AWS_REGION'],
schema_name=os.environ['AWS_ATHENA_SCHEMA'],
s3_staging_dir=quote_plus(os.environ['AWS_S3_OUT']),
wg=os.environ['AWS_ATHENA_WG']
)
, include_tables=['xtdpl1_ingressi_detailed', 'xtdpl1_ingressi_aggregated', 'xtdpl1_varchi']
, sample_rows_in_table_info=2)
# toolkit definition through Custom Class
toolkit = ExtendedSqlDatabaseToolkit(db=db, llm=OpenAI(temperature=0))
# Agent initialization
agent_executor = create_sql_agent(
llm=OpenAI(temperature=0),
toolkit=toolkit,
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION
)LangChain makes use of SQLAlchemy so it already allows accessing to a large number of DBMSs without the need of reinventing the wheel.
Note that in addition to the AWS-related environment variables explicitly referenced above, you also need to set the following variables:
- OPENAI_API_KEY: associated with the OpenAI account, which is mandatory to invoke their LLM APIs
- SERPAPI_API_KEY: associated with the SerpApi account, in order to programmatically search on Google. There is a FREE version with a 100 monthly calls limit
The options at lines 29 and 30 has been provided to limit the agent’s range of action and prevent it from making too extensive reasoning on the whole catalog and dataset. Without these options, it’s pretty easy to overcome the tokens limit in the OpenAI API call.
The toolkit instantiated at line 34 is my custom class, extending the standard SQLToolkit made available by LangChain. Being a few lines of code, I’m also adding this:
"""Enhanced Toolkit for interacting with SQL databases and search over the internet"""
from typing import List
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.tools import BaseTool
from langchain.agents import load_tools
class ExtendedSqlDatabaseToolkit(SQLDatabaseToolkit):
"""Enhanced Toolkit for interacting with SQL databases and search over the internet"""
def get_tools(self) -> List[BaseTool]:
sqlTools = super().get_tools()
additionalTools = load_tools(["serpapi"], llm=self.llm)
return additionalTools+sqlToolsPlease note that, in addition to the explicitly referenced libraries, you also need to install the “openai” and “pyathena” libraries.
The challenges
I’ve asked the agent several questions, trying to stress-test different components (eg: identifying the semantics of the data, understand what to search over the internet, when/if it’s better switching from the aggregated table to the detailed one, etc etc).
Here I’m just going to describe a couple of examples, but I will make some general considerations first.
The default language model from the OpenAI libraries is Text-davinci-003. This model is much larger and more expensive (about 10 times more!) than the one used by ChatGPT (GPT-3.5-Turbo). There are a lot of articles and papers describing the effectiveness of both in different use cases. Despite being smaller (6 vs 175 billion parameters), the latter one can have the same or in some cases even better performances.
I’ve almost exclusively used the first of the 2 and the few tests I did with GPT-3.5-Turbo had much worse results. I didn’t spend any time for trying to understand the reason for such performance gap. Maybe I will dedicate another post to this topic.
Use case A - Simple KPI Evaluation
look for the coordinates and the descriptive name of the Gate (‘varco’) with the hightest sum of diesel vehicle transits during the whole month of August 2020. Only consider the real AreaC transits and exclude the service vehicles
The returned output is represented in the following picture. If you take a look at the lines starting with “Action”, “Observation” and “Thought”, you will see that we’ve got what is expected according to the “Zero-shot ReAct” model.
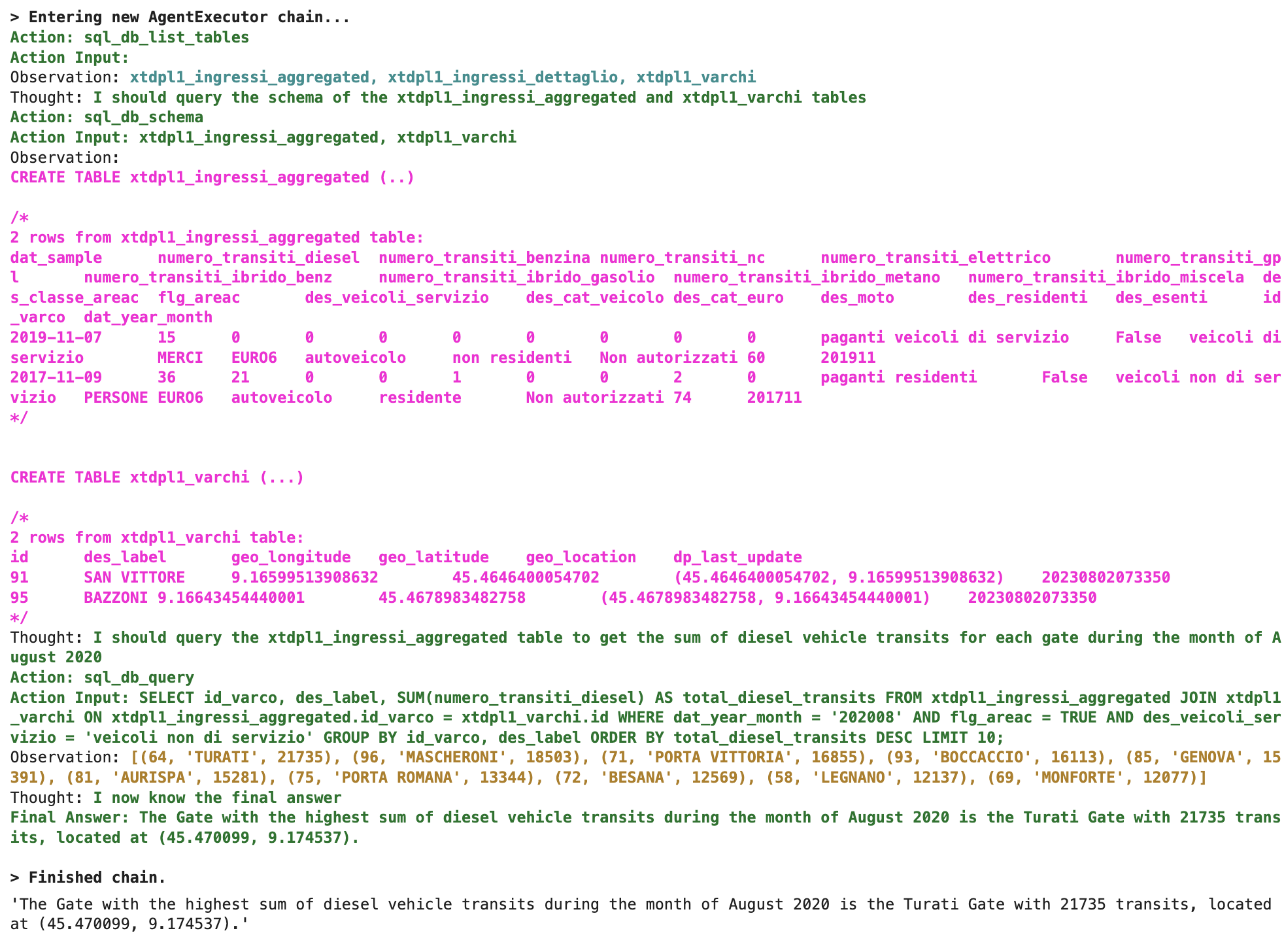
Figure 3 - Use case A output
The agent starts with the identification of the Action (sql_db_list_tables) and of the input (no input in this case), obtaining (Observation) the 3 tables on which we programmatically restricted the its visibility. In theory, the tool could explore the entire catalog but, as mentioned above, I wanted to narrow the scope to avoid exceeding the OpenAI tokens threshold.
Now the agent gives control to the LLM (Thought) to identify the next action by which it states that the only 2 interesting tables are the aggregate fact table and the gate decoding table.
Please note that it’s assuming to query the aggregated table over the detail one, but I am a little surprised that this deduction has been made solely on the table naming, since metadata and data fetching will be made later. From this point of view, the final result might not be the correct one if the 2 tables had a different data perimeter (for example if the aggregated table only contained the last year).
After fetching the metedata and extracting some sample data rows, the LLM builds the query. In this specific case you’ll see that the model guesses the syntax of the query on the first attempt, but I have experienced several cases in which it tries, correcting the syntax each time until it reaches the definitive query.
The rest is self-described in the image.
A couple of comments:
- the model was able to perfectly implement the filters I had in mind in the prompt, through naming and/or data inference
- I’ve made other few attempts by removing the aggregate table and leaving only the detail one and I got the same result. However, it should be noted that the detailed table has the KPI represented in a ROW instead of a COLUMN, so in that case the model understood that the filter “des_tipo_alimentazione = ‘diesel’” was to be applied
- as expected, no google search was done, because it was obviously not needed
Use case B - further info requested
look for the coordinates and the descriptive name of the Gate (‘varco’) with the hightest sum of diesel vehicle transits during the whole month of August 2020, including only areac entrances and excluding service vehicles. Also give me back the 3 gates with the smallest distance from it
Here, the LLM surprised me: I’ve added the final sentence to force the Agent doing a search over the internet, but I forgot that the distance could be also evaluated with mathematical operations using just geographical coordinates, therefore the tool (namely the LLM model behind it) performed the whole task within the DB as shown in Figure 8.
I’ve removed the first part of the output as this is identical to use case A.

Figure 4 - Use case B output
Use case C - combining query+search
The extreme simplicity of the data model didn’t help me so much in creating a meaningful request, so I had to do some prompt engineering in order to force a web search. Finally I managed to get something relevant with a prompt like this:
look for the coordinates and the descriptive name of the Gate (‘varco’) with the hightest sum of diesel vehicle transits during the whole month of August 2020, including only areac entrances and excluding service vehicles. Also give me back the bus stop closest to this gate

Figure 4 - Use case C output
Here I’ve experienced some differences in the Agent behaviour between the Italian and English input prompt, but in general, it’s doing the expected job.
Conclusions
As I already wrote in the previous article, the learning curve to adopt LangChain is quite shallow. A few lines of code are enough to obtain a “wow” effect and allow anyone to implement their own custom solution, also integrated with the rest of the enterprise ecosystem (repositories, Data APIs, mail servers, shared file systems, …) andß with their own LLM (for example, you can integrate your own installation of Llama 2 on-premise) where you don’t want to share data outside the Organization.
On the other hand, the examples I have given above are to be considered as simplified tutorials to familiarize yourself with the framework.
To get real solutions, a more structured approach is needed, which better exploits the characteristics of the framework and takes into account the detailed capabilities of the models.
For example, I’ve realized that it was not a wise choice to combine SQL and SerpApi search functionality in a single toolkit and that it would have been better to integrate those 2 capabilities through separate agents/chains.
As another example, I’ve noticed that in the “experimental” package there is a class called “SQLDatabaseChain” which allows you to develop a Tool Sql from scratch, with a few lines of code. This way, you can completely avoid the usage of the standard toolkit and choose a more tailored solution:
sql_chain = SQLDatabaseChain.from_llm(llm=llm, db=db, verbose=True)
sql_tool = Tool(
name='Areac DB',
func=sql_chain.run,
description="This database contains the data related to transits for all gates of the LTZ of Milan, which is called \"AreaC\""
" The most important tables are: xtdpl1_ingressi_aggregated and xtdpl1_varchi."
" The table xtdpl1_ingressi_aggregated contains most important measures, like the number of all transits for each of the gates and for each day of the year."
" The field identifying the Time dimension is 'dat_year_month' and it's NUMERIC with a standard YYYYMM format."
" The field 'flg_areac' is BOOLEAN (true/false) and it's used to identify the actual \"AreaC\" payed transits."
" The xtdpl1_varchi table contains the gates transcoding. The primary key is the 'id' field, identifying the specific gate. The other fields are descriptive attributes."
)Since the agent uses the LLM to decide which tool to use and how to use it solely based on the tool description, this approach has the great advantage of improving performance just by adding an effective description of the DB within the tool, without modifying the LLM model at all. In my case, for example, I’ve incrementally added a large number of details, experiencing every time a concrete improvement in the tool performance.